Release 0.2.1:
+ completed MySQL resource layer at pyfileserver.addons.simplemysqlabstractionlayer. See http://cwho.blogspot.com/2005/08/more-screenshots.html
+ enhanced server and abstraction layers to allow choosing to support Entity tags/last modified/contentlength and ranges on a per resource basis. e.g. a resource that does not support last modified will not return the last modified header and no last modified testing If_Modified_Since, If_Unmodified_Since is done. see in interface methods supportRanges(), supportContentLength(), etc
+ More bug fixes as they are found.
Project page: http://pyfilesync.berlios.de/
Thanks :)
Wednesday, August 31, 2005
More screenshots
Documenting the progress...
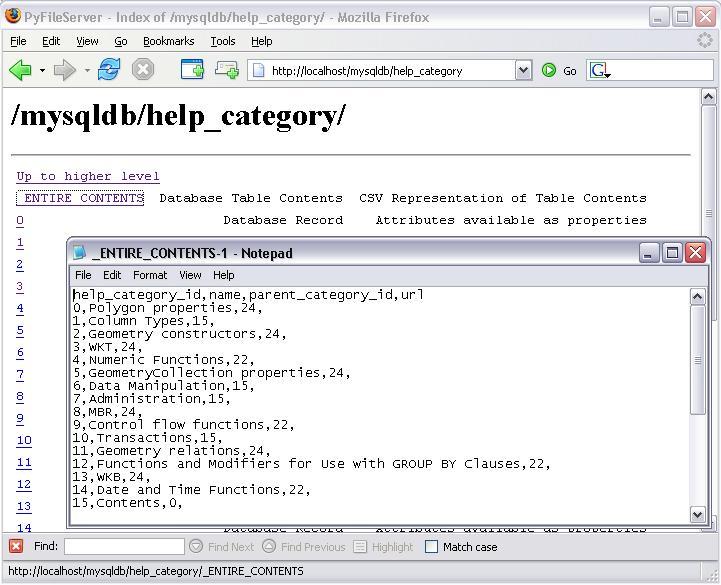
Yes, I shared the "mysql" database. Security klaxons ringing? CSV Representation is working fine.
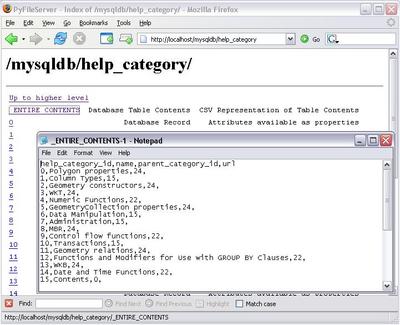
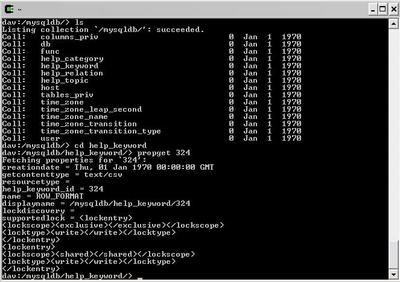
And so is live properties. cadaver doesnt show it of course, but the property namespace is ":".
Release coming up soon.
Yes, I shared the "mysql" database. Security klaxons ringing? CSV Representation is working fine.
And so is live properties. cadaver doesnt show it of course, but the property namespace is "
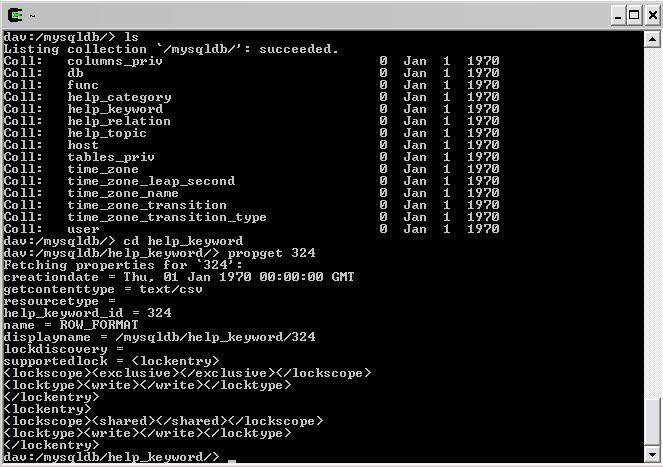
Release coming up soon.
Tuesday, August 30, 2005
Database Resource Abstraction Layer
I've just put together a sample database abstraction layer to a MySQL database, for demonstration purposes:
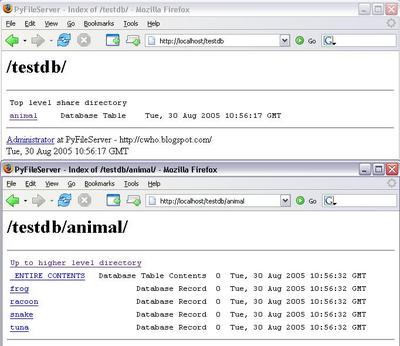
The idea (not all these features are working yet) is to allow read only access via the above methodology. _ENTIRE_CONTENTS will return a CSV representation of the data (assuming no large objects or equivalent). If the table has a SINGLE primary key, records will be listed as resources with names as those keys - these have no content but all attribute fields are available as live properties of these resources.
Trying to implement these highlighted some weaknesses in the server - it is too file oriented. Properties like modified/creation date may not mean anything to a record or table, and contentlength is a problem - there is no file size, so the only way to calculate the content length for a table.... is to retrieve ALL the content.
The solution here is to tweak the server to make these optional, such that if contentlength or modified date support is not provided, server will not use them (no last modified, no IF_(UN)MODIFIED_SINCE matching for example) or return the corresponding headers, and to support some other properties that were previously left out since they did not have too much to do with files, like getcontentlanguage.
Not all of this will appear by the SoC deadline, but most likely by mid-September (next release).
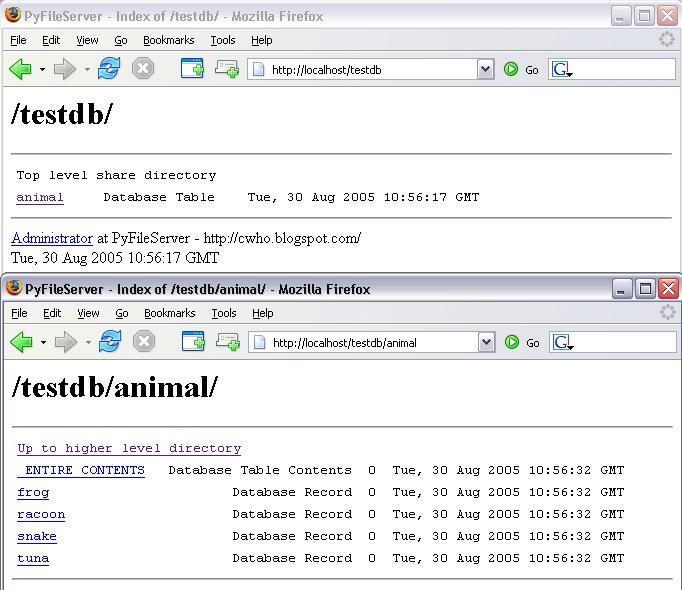
The idea (not all these features are working yet) is to allow read only access via the above methodology. _ENTIRE_CONTENTS will return a CSV representation of the data (assuming no large objects or equivalent). If the table has a SINGLE primary key, records will be listed as resources with names as those keys - these have no content but all attribute fields are available as live properties of these resources.
Trying to implement these highlighted some weaknesses in the server - it is too file oriented. Properties like modified/creation date may not mean anything to a record or table, and contentlength is a problem - there is no file size, so the only way to calculate the content length for a table.... is to retrieve ALL the content.
The solution here is to tweak the server to make these optional, such that if contentlength or modified date support is not provided, server will not use them (no last modified, no IF_(UN)MODIFIED_SINCE matching for example) or return the corresponding headers, and to support some other properties that were previously left out since they did not have too much to do with files, like getcontentlanguage.
Not all of this will appear by the SoC deadline, but most likely by mid-September (next release).
Monday, August 29, 2005
Release 0.2
Release 0.2:
+ Added resource abstraction layers. samples:
pyfileserver.fileabstraction.FilesystemAbstractionLayer and
pyfileserver.fileabstraction.ReadOnlyFilesystemAbstractionLayer
+ Removed etagprovider. Entity tags is now an aspect of the resource
abstraction layer.
+ Added interfaces pyfileserver.interfaces.*
+ cleaned up interface to lock library to make it more developer-friendly
+ More bug fixes as they are identified
Trying to make an example of using the resource layer to share resources other than files. As of this moment I am installing MySQL and reading up on MySQLdb module....
http://www.kitebird.com/articles/pydbapi.html
+ Added resource abstraction layers. samples:
pyfileserver.fileabstraction.FilesystemAbstractionLayer and
pyfileserver.fileabstraction.ReadOnlyFilesystemAbstractionLayer
+ Removed etagprovider. Entity tags is now an aspect of the resource
abstraction layer.
+ Added interfaces pyfileserver.interfaces.*
+ cleaned up interface to lock library to make it more developer-friendly
+ More bug fixes as they are identified
Trying to make an example of using the resource layer to share resources other than files. As of this moment I am installing MySQL and reading up on MySQLdb module....
http://www.kitebird.com/articles/pydbapi.html
Saturday, August 27, 2005
Release 0.1.3
Release 0.1.3:
Urgent fixes to some code in 0.1.2
Incorporated comments from code review except:
+ Architectural changes - dispatching
+ Additional information from exceptions (HTTPRequestException extended)
+ code in doMOVE / doCOPY (awaiting abstraction layer)
+ docstrings in websupportfuncs (awaiting abstraction layer)
More work on abstraction layer in progress...
Urgent fixes to some code in 0.1.2
Incorporated comments from code review except:
+ Architectural changes - dispatching
+ Additional information from exceptions (HTTPRequestException extended)
+ code in doMOVE / doCOPY (awaiting abstraction layer)
+ docstrings in websupportfuncs (awaiting abstraction layer)
More work on abstraction layer in progress...
Friday, August 26, 2005
Resource Abstraction Layer
Code is being refactored after an enlightening code review from my mentor -> thanks! :)
While that is being done (for the evaluation I think), I have also started halfway on a resource abstraction layer - that will allow the application to share resources from other sources (other than a filesystem).
A sample of the code below. I didn't want to make it too lengthy - but I've included path resolving and live properties (including etags and all the "dav" properties except the locking properties) as part of the abstraction layer, since it made sense to put them in. For example this could allow someone to share a database with tables as collections, records as resources and attributes as live properties of those resources. Thought I include the interface here as for comments.
All the code is commented (prefixed with #) since it seems blogger doesn't handle indentation well without something in front.
While that is being done (for the evaluation I think), I have also started halfway on a resource abstraction layer - that will allow the application to share resources from other sources (other than a filesystem).
A sample of the code below. I didn't want to make it too lengthy - but I've included path resolving and live properties (including etags and all the "dav" properties except the locking properties) as part of the abstraction layer, since it made sense to put them in. For example this could allow someone to share a database with tables as collections, records as resources and attributes as live properties of those resources. Thought I include the interface here as for comments.
All the code is commented (prefixed with #) since it seems blogger doesn't handle indentation well without something in front.
#class abstractionlayer(interface):
#
# def getResourceDescription(respath):
# """ returns a string containing resource description, e.g. "File", "Directory" """
#
# def getContentType(respath):
# """ returns the MIME Content-Type for resource: mimetypes.guess_type() """
#
# def getLastModified(respath):
# """ gets the Last Modified time (num of secs since epoch). Return 0 if not supported """
#
# def getContentLength(respath):
# """ gets the content length of the resource """
#
# def getEntityTag(respath):
# """ gets the entity tag for specified resource """
#
# def isCollection(respath):
# """ tests if this is a collection : os.path.isdir """
#
# def isResource(respath):
# """ tests if this is a non-collection resource : os.path.isfile """
#
# def exists(respath):
# """ tests if this resource exists : os.path.exists """
#
# def createCollection(respath):
# """ creates a collection : os.mkdir """
#
# def deleteCollection(respath):
# """ deletes a collection : os.rmdir """
#
# def openResourceForRead(respath):
# """ opens a resource for reading, returns stream """
#
# def openResourceForWrite(respath):
# """ opens a resource for writing, returns stream """
#
# def deleteResource(respath):
# """ deletes a resource : os.unlink """
#
# def copyResource(respath, destrespath):
# """ copies a resource : shutils.copy2 """
#
# def getContainingCollection(respath):
# """ returns the path of the collection containg the resource : os.path.dirname """
#
# def getContentsList(respath):
# """ returns a list of names of resources in this collection
# it is based on the assumption that names returned can be joinPath() with
# the specified path to form the path to the resource
# : os.listdir
# """
#
# def joinPath(rescollectionpath, resname):
# """ Joins the two path components intelligently : os.path.join """
#
# def splitPath(respath):
# """ Splits a path returning a tuple (containg collection path, # resource name) : os.path.split
# """
#
# def getProperty(respath, propertyname, propertyns):
# """ returns property value for resource. This should implement all the required
# webdav properties except locking properties
# """
#
# def isPropertySupported(respath, propertyname, propertyns):
# """ tests if the specified property is a live property supported. If it is not
# supported, the application will look for it in the dead properties library
# """
#
# def resolvePath(resheadpath, urlelementlist):
# """ resolves the given url sequence to a path. Example:
# the directory c:\Test was shared as http://localhost/testing/.
# Then user accessing http://localhost/testing/dir1/dir2/file1.txt
# will require resolvePath to return a valid path to file1.txt from
# resolvePath('c:\Test', ['dir1','dir2','file1.txt'].
#
# An exception exiting this function may result in return of a 404 File Not Found
# """
Tuesday, August 23, 2005
Release 0.1.2
Release 0.1.2:
+ Minor fixes to Tutorial
+ Added windowsdomaincontroller under pyfileserver.addons
+ Added Addons documentation section
The windowsdomaincontroller allows the user to authenticate against a Windows NT domain or a local computer, requires NT or beyond (2000, XP, 2003, etc).
This class requires Mark Hammond's Win32 extensions for Python:
http://starship.python.net/crew/mhammond/win32/Downloads.html
http://sourceforge.net/projects/pywin32/
Information on Win32 network authentication was from the following resources:
http://ejabberd.jabber.ru/node/55
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/81402
+ Minor fixes to Tutorial
+ Added windowsdomaincontroller under pyfileserver.addons
+ Added Addons documentation section
The windowsdomaincontroller allows the user to authenticate against a Windows NT domain or a local computer, requires NT or beyond (2000, XP, 2003, etc).
This class requires Mark Hammond's Win32 extensions for Python:
http://starship.python.net/crew/mhammond/win32/Downloads.html
http://sourceforge.net/projects/pywin32/
Information on Win32 network authentication was from the following resources:
http://ejabberd.jabber.ru/node/55
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/81402
Friday, August 19, 2005
Release 0.1.1
Just released PyFileServer 0.1.1
+ Fixed up setup.py
+ Added Tutorial to documentation
+ Now sends 401 for invalid auth request instead of 404
+ disable realm checking - partial hotfix for WinXP webdav redirector
remembering auth details for the same user using it for different
realms (since it is the same host)
+ Other misc bugs.
+ Fixed up setup.py
+ Added Tutorial to documentation
+ Now sends 401 for invalid auth request instead of 404
+ disable realm checking - partial hotfix for WinXP webdav redirector
remembering auth details for the same user using it for different
realms (since it is the same host)
+ Other misc bugs.
Wednesday, August 17, 2005
What it should have been
I was using the term
In summary,
dbm previously when I meant standard database connection, which I had in mind the SimpleSessionServer from WSGIUtils. It didn't really hit me till right now that shelve is implemented over dbm, and anyway SimpleSessionServer uses sockets to communicate with a anydbm repository.
In summary,
shelve already uses dbm (the standard db interface). I really pulled a Charlie Gordon on this one.
Tuesday, August 16, 2005
Week 7
Progress In Project
Following the release of 0.1, pace of development has slowed down a bit. I ran out of items sitting on the list that could just be done, the others require some research...
These days, I am (in this order of priorities):
+ Reading up and experimenting with
+ Attempting to debug inconsistencies with authentication that WinXP Network Places has with the server. Not having too much luck with this, there must be something I am missing.
+ Getting setup tools to use
Google Code Jam
Like any enthusastic coder, of course I signed up for the Google Code Jam :). I tried out practice set 1, and was having trouble understanding their solution to the DiskDefrag problem (given a number of discontiguous files in a set of blocks simulating a filesystem, compute the minimum number of moves/block moving operations required to have all files in contiguous order.) The solution uses some sort of dynamic programming, but the mathematics/logic is still boiling around in my mind.
I tried a different approach by generating all valid contiguous ordered file position combinations in the filesystem and looking for the minimum number of moves from the current position to one of these valid positions. For max of 12 files and 100 block size this does not appear to be overwhelmingly intensive (but does not scale well). It worked for several test cases but running the full test shows it does not run (expectedly) within a previously-unmentioned 2 seconds limit for some test cases. Back to the drawing board.
MOBA
For anyone who was puzzled by one of the comments of the previous post, MOBA = My Own BS Algorithm, commonly refering to self-known or self-invented hacks. It is no coincidence that "a MOBA" (also known as AMOEBA) is a large single cellular organism, just like unmodular code.
I'll let users be the judge if MOBA is in the code. :)
Following the release of 0.1, pace of development has slowed down a bit. I ran out of items sitting on the list that could just be done, the others require some research...
These days, I am (in this order of priorities):
+ Reading up and experimenting with
dbm (to try and package a database backed lock and poperties library with the server other than the existing shelve based libraries)
+ Attempting to debug inconsistencies with authentication that WinXP Network Places has with the server. Not having too much luck with this, there must be something I am missing.
+ Getting setup tools to use
install_requires properly to download and install PyXML. Right now it does not find PyXML over PyPI, so instead I replaced it with a manual check and a print message that PyXML is required.
Google Code Jam
Like any enthusastic coder, of course I signed up for the Google Code Jam :). I tried out practice set 1, and was having trouble understanding their solution to the DiskDefrag problem (given a number of discontiguous files in a set of blocks simulating a filesystem, compute the minimum number of moves/block moving operations required to have all files in contiguous order.) The solution uses some sort of dynamic programming, but the mathematics/logic is still boiling around in my mind.
I tried a different approach by generating all valid contiguous ordered file position combinations in the filesystem and looking for the minimum number of moves from the current position to one of these valid positions. For max of 12 files and 100 block size this does not appear to be overwhelmingly intensive (but does not scale well). It worked for several test cases but running the full test shows it does not run (expectedly) within a previously-unmentioned 2 seconds limit for some test cases. Back to the drawing board.
MOBA
For anyone who was puzzled by one of the comments of the previous post, MOBA = My Own BS Algorithm, commonly refering to self-known or self-invented hacks. It is no coincidence that "a MOBA" (also known as AMOEBA) is a large single cellular organism, just like unmodular code.
I'll let users be the judge if MOBA is in the code. :)
Wednesday, August 10, 2005
File Release
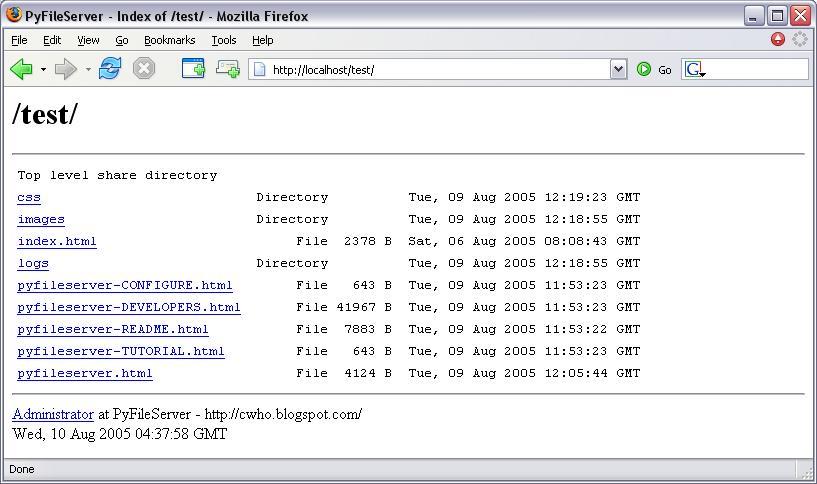
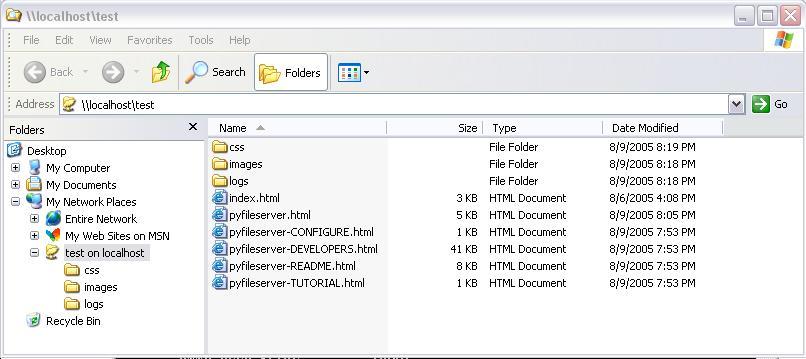
I just released version 0.1.
XP support, despite what you see here, is not too perfect yet. Its buggy in a sense, XP Network Places appears to remember your successful authentication details the first time, and then either submit those details for a different user/realm, or refuse to accept new details (request header monitoring shows that it does not submit the authentication header for the new details).
Working out those details... and also picking up misc bugs around the place.
Monday, August 08, 2005
Week 6
WebDAV functionality
Locks - Done. Working with both litmus and DAVExplorer. DAVExplorer tends to be a tad buggy in this respect. After a while it seems to forget that the resource is locked and does not submit a If header - has to be 'reminded' by locking/unlocking.
XP WebDAV support - works. Earlier today I was able to mount it on my Network Places, browse the filespace, read files, copy files from local drive onto the filespace, create folders, move/copy files within the filespace, delete files. Will continue to play with it. There does not appear to be a locking functionality.
cadaver - will be tested soon, but I don't really expect any major hiccups.
What's next?
Initial File Release (I just want to release something). And then:
A lot of cleaning code:
+ Setting a proper verbose option and removing all the out-of-place-for-debugging print statements
+ I need to figure out how logging is used (
+ Catch "Software Caused Connection Abort" exceptions and stop them from spamming the screen and drowning real exceptions. They are thrown when the client closes the connection even before the whole response is transmitted, since the response code is the first thing it gets - and needs. Quite the literal slamming down the phone before the other side has finished his piece, but its also quite common. :)
Better structuring:
+ Cleaning up the locks manager interface. Right now its a mess of functions defined and named at-hoc.
+ If time permits, I like to make another set of locksmanager, propertymanager, domaincontroller, this time based on a database (probably
Locks - Done. Working with both litmus and DAVExplorer. DAVExplorer tends to be a tad buggy in this respect. After a while it seems to forget that the resource is locked and does not submit a If header - has to be 'reminded' by locking/unlocking.
XP WebDAV support - works. Earlier today I was able to mount it on my Network Places, browse the filespace, read files, copy files from local drive onto the filespace, create folders, move/copy files within the filespace, delete files. Will continue to play with it. There does not appear to be a locking functionality.
cadaver - will be tested soon, but I don't really expect any major hiccups.
What's next?
Initial File Release (I just want to release something). And then:
A lot of cleaning code:
+ Setting a proper verbose option and removing all the out-of-place-for-debugging print statements
+ I need to figure out how logging is used (
logging the standard module), and if it is something that should be standardize within my code
+ Catch "Software Caused Connection Abort" exceptions and stop them from spamming the screen and drowning real exceptions. They are thrown when the client closes the connection even before the whole response is transmitted, since the response code is the first thing it gets - and needs. Quite the literal slamming down the phone before the other side has finished his piece, but its also quite common. :)
Better structuring:
+ Cleaning up the locks manager interface. Right now its a mess of functions defined and named at-hoc.
+ If time permits, I like to make another set of locksmanager, propertymanager, domaincontroller, this time based on a database (probably
dbm). I am slightly unhappy with the performance and usability of the existing shelve components
Saturday, August 06, 2005
Week 5: Ends
So ends Week 5.
Locks
Posted on the litmus mailing list for some strange results I was getting, seems like I got the locks/If-header handling part wrong (again!). Thanks to Julian Reschke who has been answering a lot of my queries on the specification on litmus@webdav.org and w3c-dist-auth@w3.org lists
Reworking....
Testing
Win XP Network Places still refuses to recognize the webdav server, but thankfully I googled first before jumping in with the gearbox, there is a thread and some resources that address this problem in depth:
http://lists.w3.org/Archives/Public/w3c-dist-auth/2002JanMar/0064.html
http://greenbytes.de/tech/webdav/webdav-redirector-list.html
Documentation
Have the modules moderately documented and cooking up some standalone documentation.
Distribution
At my mentor's suggestion I looked up setuptools http://peak.telecommunity.com/DevCenter/setuptools, which is much easier to use than distutils. I like to think I got a working setup.py cooked up, but I have not tested it yet.
CVS and SVN
In miscellaneous refactoring and renaming to be compliant with PEP-8, I had to rename some of my files and directories to fully lowercase. While CVS and SVN both do not allow case only renames, SVN at least has a standard workaround. SVN is fully updated with the latest code.
All the CVS workarounds that I managed to google did not work out, so I am abandoning the CVS repository. The current version has the tree wiped and CVS anonymous access has been disabled.
Locks
Posted on the litmus mailing list for some strange results I was getting, seems like I got the locks/If-header handling part wrong (again!). Thanks to Julian Reschke who has been answering a lot of my queries on the specification on litmus@webdav.org and w3c-dist-auth@w3.org lists
Reworking....
Testing
Win XP Network Places still refuses to recognize the webdav server, but thankfully I googled first before jumping in with the gearbox, there is a thread and some resources that address this problem in depth:
http://lists.w3.org/Archives/Public/w3c-dist-auth/2002JanMar/0064.html
http://greenbytes.de/tech/webdav/webdav-redirector-list.html
Documentation
Have the modules moderately documented and cooking up some standalone documentation.
Distribution
At my mentor's suggestion I looked up setuptools http://peak.telecommunity.com/DevCenter/setuptools, which is much easier to use than distutils. I like to think I got a working setup.py cooked up, but I have not tested it yet.
CVS and SVN
In miscellaneous refactoring and renaming to be compliant with PEP-8, I had to rename some of my files and directories to fully lowercase. While CVS and SVN both do not allow case only renames, SVN at least has a standard workaround. SVN is fully updated with the latest code.
All the CVS workarounds that I managed to google did not work out, so I am abandoning the CVS repository. The current version has the tree wiped and CVS anonymous access has been disabled.
Wednesday, August 03, 2005
Wednesday
Today was less productive on coding, starting preparation on other portions.
+ Managed to get a project page up. This one wouldnt win any web design awards tho. http://pyfilesync.berlios.de/
+ Did misc administration, categorizing and feature selection/cleanup of the "pyfilesync" project on BerliOS proper. Finally managed to get anonymous SVN access working, the SVN feature has to be enabled (only CVS is enabled by default) for the project. So.... I can create an SVN repository, populate it and share its contents with team members with the SVN feature disabled, but anonymous SVN access, now that requires enabling the feature.... intuitive?
+ Looking at File Modules and Releases on BerliOS next
+ Reading on setuptools and reStruturedText for packaging and documentation
+ Testing and debugging (still trying to get DAVExplorer to work with locks)
University starts next week, just chose my modules today, and I am already planning on skipping classes :)
+ Managed to get a project page up. This one wouldnt win any web design awards tho. http://pyfilesync.berlios.de/
+ Did misc administration, categorizing and feature selection/cleanup of the "pyfilesync" project on BerliOS proper. Finally managed to get anonymous SVN access working, the SVN feature has to be enabled (only CVS is enabled by default) for the project. So.... I can create an SVN repository, populate it and share its contents with team members with the SVN feature disabled, but anonymous SVN access, now that requires enabling the feature.... intuitive?
+ Looking at File Modules and Releases on BerliOS next
+ Reading on setuptools and reStruturedText for packaging and documentation
+ Testing and debugging (still trying to get DAVExplorer to work with locks)
University starts next week, just chose my modules today, and I am already planning on skipping classes :)
Tuesday, August 02, 2005
Operation Atomcity
This is the second blog post for today, but it really belongs as a separate topic.
This just hit me while I was mucking around finalizing the locking code. There might be an issue with concurrent requests, since the webDAV is running off the file system directly.
For example, if a file is constantly GETed, there will be no way to DELETE it since delete will fail because the file is always open for reading for the GET processes. Denial of Delete Service attack? There are potential clashes like this that could cause methods like MOVE or COPY to fail, even if the client does all the proper LOCKing beforehand.
The simple fix is to put a threading.RLock over all the operations, so that only one operation is being done, and done to completion before the next one comes in, but this really limits the server to a pseudo -single thread- operation, which is really means no concurrency support. The complex way would be to define locks such that operations can only be carried out concurrently if they do not conflict, defined loosely as if the two requests are not direct ancestor/descendants of each other in the file structure (since operations can have Depth == infinity).
I am just wondering if this level of robustness is required here......
This just hit me while I was mucking around finalizing the locking code. There might be an issue with concurrent requests, since the webDAV is running off the file system directly.
For example, if a file is constantly GETed, there will be no way to DELETE it since delete will fail because the file is always open for reading for the GET processes. Denial of Delete Service attack? There are potential clashes like this that could cause methods like MOVE or COPY to fail, even if the client does all the proper LOCKing beforehand.
The simple fix is to put a threading.RLock over all the operations, so that only one operation is being done, and done to completion before the next one comes in, but this really limits the server to a pseudo -single thread- operation, which is really means no concurrency support. The complex way would be to define locks such that operations can only be carried out concurrently if they do not conflict, defined loosely as if the two requests are not direct ancestor/descendants of each other in the file structure (since operations can have Depth == infinity).
I am just wondering if this level of robustness is required here......
The server is done
The webDAV server is done! I finished locking today, ran through the whole series of neon-litmus tests today and everything fell through:
cwho@CHIMAERA /cygdrive/c/Soc/litmus-0.10.2/litmus-0.10.2
$ litmus http://localhost:8080/test/ tester tester
-> running `basic':
...
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
...
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
...
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
-> running `locks':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. precond............... pass
4. init_locks............ pass
5. put................... pass
6. lock_excl............. pass
7. discover.............. pass
8. refresh............... pass
9. notowner_modify....... pass
10. notowner_lock......... pass
11. owner_modify.......... pass
12. notowner_modify....... pass
13. notowner_lock......... pass
14. copy.................. pass
15. cond_put.............. pass
16. fail_cond_put......... pass
17. cond_put_with_not..... pass
18. cond_put_corrupt_token pass
19. complex_cond_put...... pass
20. fail_complex_cond_put. pass
21. unlock................ pass
22. lock_shared........... pass
23. notowner_modify....... pass
24. notowner_lock......... pass
25. owner_modify.......... pass
26. double_sharedlock..... pass
27. notowner_modify....... pass
28. notowner_lock......... pass
29. unlock................ pass
30. prep_collection....... pass
31. lock_collection....... pass
32. owner_modify.......... pass
33. notowner_modify....... pass
34. refresh............... pass
35. indirect_refresh...... pass
36. unlock................ pass
37. finish................ pass
<- summary for `locks': of 38 tests run: 38 passed, 0 failed. 100.0%
-> running `http':
0. init.................. pass
1. begin................. pass
2. expect100............. pass
3. finish................ pass
<- summary for `http': of 4 tests run: 4 passed, 0 failed. 100.0%
I will continue testing with standard webDAV clients:
+ DAVExplorer 0.91 (Java-based)
Did some testing, the normal operations work but locking still needs working out. More debugging...
+ Cadaver 0.22.2 (just managed to compile it over cygwin)
Also in the priority queue are:
+ packaging and layout
+ conversion of tab-indents to 4-indent
+ misc refactoring
Some accumulated low priority TODOs throughout:
+ Figure out what the warning for litmus: "WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe" is
+ Gzip support for Content-Encoding (a challenge to support with Content-Ranges)
+ More support for null resource locking -> this is slightly hard to do since I have been relying on the file system itself as the arbiter of what is there and what is not.
+ Encryption -> SSL support would probably be a property of the web server itself.
cwho@CHIMAERA /cygdrive/c/Soc/litmus-0.10.2/litmus-0.10.2
$ litmus http://localhost:8080/test/ tester tester
-> running `basic':
...
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
...
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
...
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
-> running `locks':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. precond............... pass
4. init_locks............ pass
5. put................... pass
6. lock_excl............. pass
7. discover.............. pass
8. refresh............... pass
9. notowner_modify....... pass
10. notowner_lock......... pass
11. owner_modify.......... pass
12. notowner_modify....... pass
13. notowner_lock......... pass
14. copy.................. pass
15. cond_put.............. pass
16. fail_cond_put......... pass
17. cond_put_with_not..... pass
18. cond_put_corrupt_token pass
19. complex_cond_put...... pass
20. fail_complex_cond_put. pass
21. unlock................ pass
22. lock_shared........... pass
23. notowner_modify....... pass
24. notowner_lock......... pass
25. owner_modify.......... pass
26. double_sharedlock..... pass
27. notowner_modify....... pass
28. notowner_lock......... pass
29. unlock................ pass
30. prep_collection....... pass
31. lock_collection....... pass
32. owner_modify.......... pass
33. notowner_modify....... pass
34. refresh............... pass
35. indirect_refresh...... pass
36. unlock................ pass
37. finish................ pass
<- summary for `locks': of 38 tests run: 38 passed, 0 failed. 100.0%
-> running `http':
0. init.................. pass
1. begin................. pass
2. expect100............. pass
3. finish................ pass
<- summary for `http': of 4 tests run: 4 passed, 0 failed. 100.0%
I will continue testing with standard webDAV clients:
+ DAVExplorer 0.91 (Java-based)
Did some testing, the normal operations work but locking still needs working out. More debugging...
+ Cadaver 0.22.2 (just managed to compile it over cygwin)
Also in the priority queue are:
+ packaging and layout
+ conversion of tab-indents to 4-indent
+ misc refactoring
Some accumulated low priority TODOs throughout:
+ Figure out what the warning for litmus: "WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe" is
+ Gzip support for Content-Encoding (a challenge to support with Content-Ranges)
+ More support for null resource locking -> this is slightly hard to do since I have been relying on the file system itself as the arbiter of what is there and what is not.
+ Encryption -> SSL support would probably be a property of the web server itself.
Monday, August 01, 2005
Week 5: Locks
Locks got off to a good start.
Locks Managing
Unlike dead properties, locks was slightly more complex to model as a locks over it.
What I did was to store the information in a slightly redundant way. Each lock stored which urls it locked, and each url stored which locks was applicable over it.
Since
where
This does mean no support for concurrency - only one writing Lock operation can be performed at any one time.
Test Status
Is too ugly to put on the blog at the moment. Let's just say that I got what I want for locks coded, except for write locks over null resources and adding new resources to existing collection locks. But there is a lot of debugging to be done.
One big realization coming out of this is how important tests are. Initially I was writing code that I knew worked and letting the tests verify what I knew (something like a rubberstamp), but as the project goes along I am increasingly relying on tests to catch what I should have caught in coding.
One thing for sure, I could not have made such progress without the litmus test suite. Having to write out, code and conduct the tests alone would have taken me about as much time as I spend on the server.
Locks Managing
Unlike dead properties, locks was slightly more complex to model as a
shelve dict structure, since its really two structures - locks and urls. Each lock is applied over a number of urls, and one url could have several What I did was to store the information in a slightly redundant way. Each lock stored which urls it locked, and each url stored which locks was applicable over it.
Since
shelve sub-dicts (that is, dictionaries and other data structures that are themselves value elements within the shelve dict) are retrieved, manipulated in memory and then written back to the repository on sync, this duplicated structure meant that two concurrent lock operations over the same resource could make the two sub-dicts inconsistent with each other by writing the wrong structure at the wrong time. What I did was to use threading such that:
def writinglockoperation(self, args):
...self._write_lock.acquire(blocking=True)
...try:
......doStuff...
...finally:
......self._dict.sync()
......self._write_lock.release()
where
self._dict is the shelve dict and self._write_lock is a threading.RLockThis does mean no support for concurrency - only one writing Lock operation can be performed at any one time.
Test Status
Is too ugly to put on the blog at the moment. Let's just say that I got what I want for locks coded, except for write locks over null resources and adding new resources to existing collection locks. But there is a lot of debugging to be done.
One big realization coming out of this is how important tests are. Initially I was writing code that I knew worked and letting the tests verify what I knew (something like a rubberstamp), but as the project goes along I am increasingly relying on tests to catch what I should have caught in coding.
One thing for sure, I could not have made such progress without the litmus test suite. Having to write out, code and conduct the tests alone would have taken me about as much time as I spend on the server.
Subscribe to:
Comments (Atom)