Saturday, December 31, 2005
Monday, December 19, 2005
Messenging Galore
Sorry that there hasn't been any entries till today. I've been slightly busy. Academic. Home searching. No t-shirt from Google yet, but I believe in Christmas surprises :)
Just cleaned up my system yesterday, and took stock note of the number of internet messenging clients I use to keep up to date with diverse groups of friends, fellow professionals and family. Let's see:
- MSN Messenger
- Hamachi (the VPN functionality is really useful)
- Yahoo Messenger
- Skype
- Google Talk
How many internet messenging clients do YOU use?
Just cleaned up my system yesterday, and took stock note of the number of internet messenging clients I use to keep up to date with diverse groups of friends, fellow professionals and family. Let's see:
- MSN Messenger
- Hamachi (the VPN functionality is really useful)
- Yahoo Messenger
- Skype
- Google Talk
How many internet messenging clients do YOU use?
Wednesday, October 26, 2005
This Day
SoC Results
Google posted the SoC results:
http://googleblog.blogspot.com/2005/10/supporting-open-source.html
I'm not on the map yet, but its still being updated.
=> Update: I'm now on the map.
Google posted the SoC results:
http://googleblog.blogspot.com/2005/10/supporting-open-source.html
I'm not on the map yet, but its still being updated.
=> Update: I'm now on the map.
Tuesday, October 04, 2005
Aftermath
The Good and Grateful
There hasn't been much entries after the completion of the program (not the project - which is still undergoing work, albeit much slowly since it gets interrupted by school assignments and the like). I did want to thank Google, Python Software Foundation and my mentor Ian Bicking again for offering the opportunity and providing the help throughout the project. I learnt a lot, technical wse - considering that this was my first foray into Python web services.
That linuxgazette article
Most of the reaction from the open source developer and academic community to the SoC program has been good. Admittedly there were a few kinks here and there, but nothing less would be expected on the first run of program. It was quite successful, and I am sure this experience will help for the next one (Code of Summer, or Code of Winter?).
What left a bad taste in my mouth was this linuxgazette article covering the "aftermath" of the event - "After the Summer of Code" (no, you don't have to read it to follow my criticism). The article points out criticism to the program, for which I do give it dubious merit, its hard to come out and point an accusing finger at a popular program.
But that's a nasty piece of journalism. Rather than presenting a coherent and informative description of the program and its faults (if any), it instead throws out random complaints elicited from various web pages and mailing lists (probably without even contacting the malefactors involved to see if their complaints had been true or successfully resolved), and turn them into rants.
It starts off with:
One of the biggest noises.... right.... An article is not a blog like this.
The article proceeds to reference the experience given a mentor, who gives some very useful and honest advice to future candidates. But instead of giving a balanced summary of its contents, the linuxgazette article quotes a paragraph from the "BAD APPLICATIONS" section and presents it as _A SUMMARY_ of the selection process, not only distorting meaning but giving the idea that the informative piece was no more than a rant about the quality of applications received.
The article proceeds to contradict itself with its criticism of the amount of "reward" given, USD4500. At first it mentioned that this was far too small for 2 months work, well below what a summer intern would earn in the US. In subsequent sections, it reversed its stance and pointed out that the reward was well above what other open source organizations are offering for contributions. I guess you can't make everyone happy.
Next, it draws attention to the imbalance in scope and perceived usefulness of selected projects (which is to be expected, given the diversity of mentoring organizations and students accepted), but particularly single out WinLibre for sponsoring three similar updating projects, and termed it a waste of money. You can draw your own conclusion, but IMHO the open source development model does encourage a certain amount of redundancy. What disgusted me was the utter lack of courtesy paid to those projects, when in the list of projects to follow, instead of listing these projects by name (obtainable by simply following the link) [python_rewrite_bertrand, updater, bodq], the author lists them as [Python/XML installer/updater, Another updater, Yet another installer/updater].
Finally, the list of projects provided in the article was incomplete, and totally fails to take into account that each project's scope, name and page location has changed since the commencement of the project. Perhaps the author should have contacted Google, to obtain the information provided at the conclusion of the program.
Now I usually have some respect for experienced professionals sharing their experiences on linuxgazette, especially with articles like "Learning to Program with DrScheme" (just before the offending article) and "Optimizing Website Images with the Littleutils" (just after), but I have to say that "After the Summer of Code" falls short of expectations.
There hasn't been much entries after the completion of the program (not the project - which is still undergoing work, albeit much slowly since it gets interrupted by school assignments and the like). I did want to thank Google, Python Software Foundation and my mentor Ian Bicking again for offering the opportunity and providing the help throughout the project. I learnt a lot, technical wse - considering that this was my first foray into Python web services.
That linuxgazette article
Most of the reaction from the open source developer and academic community to the SoC program has been good. Admittedly there were a few kinks here and there, but nothing less would be expected on the first run of program. It was quite successful, and I am sure this experience will help for the next one (Code of Summer, or Code of Winter?).
What left a bad taste in my mouth was this linuxgazette article covering the "aftermath" of the event - "After the Summer of Code" (no, you don't have to read it to follow my criticism). The article points out criticism to the program, for which I do give it dubious merit, its hard to come out and point an accusing finger at a popular program.
But that's a nasty piece of journalism. Rather than presenting a coherent and informative description of the program and its faults (if any), it instead throws out random complaints elicited from various web pages and mailing lists (probably without even contacting the malefactors involved to see if their complaints had been true or successfully resolved), and turn them into rants.
It starts off with:
One of the biggest noises in Open Source this year was made by Google's announcement of the Summer of Code: a project to encourage students to participate in the development of open source projects during the summer holidays. One of the biggest noises.... right.... An article is not a blog like this.
The article proceeds to reference the experience given a mentor, who gives some very useful and honest advice to future candidates. But instead of giving a balanced summary of its contents, the linuxgazette article quotes a paragraph from the "BAD APPLICATIONS" section and presents it as _A SUMMARY_ of the selection process, not only distorting meaning but giving the idea that the informative piece was no more than a rant about the quality of applications received.
The article proceeds to contradict itself with its criticism of the amount of "reward" given, USD4500. At first it mentioned that this was far too small for 2 months work, well below what a summer intern would earn in the US. In subsequent sections, it reversed its stance and pointed out that the reward was well above what other open source organizations are offering for contributions. I guess you can't make everyone happy.
Next, it draws attention to the imbalance in scope and perceived usefulness of selected projects (which is to be expected, given the diversity of mentoring organizations and students accepted), but particularly single out WinLibre for sponsoring three similar updating projects, and termed it a waste of money. You can draw your own conclusion, but IMHO the open source development model does encourage a certain amount of redundancy. What disgusted me was the utter lack of courtesy paid to those projects, when in the list of projects to follow, instead of listing these projects by name (obtainable by simply following the link) [python_rewrite_bertrand, updater, bodq], the author lists them as [Python/XML installer/updater, Another updater, Yet another installer/updater].
Finally, the list of projects provided in the article was incomplete, and totally fails to take into account that each project's scope, name and page location has changed since the commencement of the project. Perhaps the author should have contacted Google, to obtain the information provided at the conclusion of the program.
Now I usually have some respect for experienced professionals sharing their experiences on linuxgazette, especially with articles like "Learning to Program with DrScheme" (just before the offending article) and "Optimizing Website Images with the Littleutils" (just after), but I have to say that "After the Summer of Code" falls short of expectations.
Thursday, September 15, 2005
PyFileServer
The code for this project is available at:
Anonymous SVN: svn://svn.berlios.de/pyfilesync
Instructions here if you have difficulties.
Contact: fuzzybr80(at)gmail(dot)com
Anonymous SVN: svn://svn.berlios.de/pyfilesync
Instructions here if you have difficulties.
Contact: fuzzybr80(at)gmail(dot)com
Tuesday, September 13, 2005
SVN and PyFileServer
Long time no post. No recent news on PyFileServer, except that I've submitted the DDJ SOC article.
Today I got an email expressing interest in PyFileServer (a good day!!) and wondering if it could be used to host an SVN repository. So I checked out the SVN internals and how its being accessed:
+ as a http(s):// url - with the server as Apache mod_svn_dav, using a partial/customized version of WebDAV and DeltaV
+ as a svn(+tunnel):// url - with the server as svnserve, using its own custom protocol
+ as a file:// url - using the ra_local library to access the repository directly.
PyFileServer was designed to allow custom resource layers (and lock/property libraries) to be implemented. For PyFileServer to host a SVN repository, the simplest solution might be:
[svn repos-file] <---- ra_local ------> [PyFileServer] <------ webdav ------> [svn client]
(1) I'll write a SVN abstraction layer that accesses a local repository (via ra_local). This allows PyFileServer users to browse and retrieve SVN repos contents, via webDAV clients.
(2) I'll extend the PyFileServer application to include DeltaV extensions to WebDAV. This allows the actual versioning portion (checkin/checkout), via webDAV clients.
(3) Here's this bit that provides difficulty - svn client and mod_svn_dav uses a partial/customized version of WebDAV/DeltaV to communicate, and its not documented in detail:
+ http://svnbook.red-bean.com/en/1.0/apcs02.html
+ http://svn.collab.net/repos/svn/trunk/subversion/libsvn_ra_dav/protocol
So while you'll be able to access the SVN repository via webDAV clients, you would not be able to do "svn co URL" where URL is PyFileServer hosted, unless PyFileServer reimplement or bind over mod_svn_dav in some way to speak their language.
I would be doing (1) and (2) on the way, as my studies and other projects allow. However, (3) might not be done for quite a while, so if you were wanting to use this for a production/workplace setup, you probably will not wait for it.
Today I got an email expressing interest in PyFileServer (a good day!!) and wondering if it could be used to host an SVN repository. So I checked out the SVN internals and how its being accessed:
+ as a http(s):// url - with the server as Apache mod_svn_dav, using a partial/customized version of WebDAV and DeltaV
+ as a svn(+tunnel):// url - with the server as svnserve, using its own custom protocol
+ as a file:// url - using the ra_local library to access the repository directly.
PyFileServer was designed to allow custom resource layers (and lock/property libraries) to be implemented. For PyFileServer to host a SVN repository, the simplest solution might be:
[svn repos-file] <---- ra_local ------> [PyFileServer] <------ webdav ------> [svn client]
(1) I'll write a SVN abstraction layer that accesses a local repository (via ra_local). This allows PyFileServer users to browse and retrieve SVN repos contents, via webDAV clients.
(2) I'll extend the PyFileServer application to include DeltaV extensions to WebDAV. This allows the actual versioning portion (checkin/checkout), via webDAV clients.
(3) Here's this bit that provides difficulty - svn client and mod_svn_dav uses a partial/customized version of WebDAV/DeltaV to communicate, and its not documented in detail:
+ http://svnbook.red-bean.com/en/1.0/apcs02.html
+ http://svn.collab.net/repos/svn/trunk/subversion/libsvn_ra_dav/protocol
So while you'll be able to access the SVN repository via webDAV clients, you would not be able to do "svn co URL" where URL is PyFileServer hosted, unless PyFileServer reimplement or bind over mod_svn_dav in some way to speak their language.
I would be doing (1) and (2) on the way, as my studies and other projects allow. However, (3) might not be done for quite a while, so if you were wanting to use this for a production/workplace setup, you probably will not wait for it.
Wednesday, August 31, 2005
Release 0.2.1
Release 0.2.1:
+ completed MySQL resource layer at pyfileserver.addons.simplemysqlabstractionlayer. See http://cwho.blogspot.com/2005/08/more-screenshots.html
+ enhanced server and abstraction layers to allow choosing to support Entity tags/last modified/contentlength and ranges on a per resource basis. e.g. a resource that does not support last modified will not return the last modified header and no last modified testing If_Modified_Since, If_Unmodified_Since is done. see in interface methods supportRanges(), supportContentLength(), etc
+ More bug fixes as they are found.
Project page: http://pyfilesync.berlios.de/
Thanks :)
+ completed MySQL resource layer at pyfileserver.addons.simplemysqlabstractionlayer. See http://cwho.blogspot.com/2005/08/more-screenshots.html
+ enhanced server and abstraction layers to allow choosing to support Entity tags/last modified/contentlength and ranges on a per resource basis. e.g. a resource that does not support last modified will not return the last modified header and no last modified testing If_Modified_Since, If_Unmodified_Since is done. see in interface methods supportRanges(), supportContentLength(), etc
+ More bug fixes as they are found.
Project page: http://pyfilesync.berlios.de/
Thanks :)
More screenshots
Documenting the progress...
Yes, I shared the "mysql" database. Security klaxons ringing? CSV Representation is working fine.
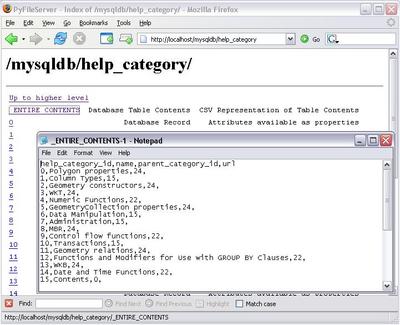
And so is live properties. cadaver doesnt show it of course, but the property namespace is ":".
Release coming up soon.
Yes, I shared the "mysql" database. Security klaxons ringing? CSV Representation is working fine.
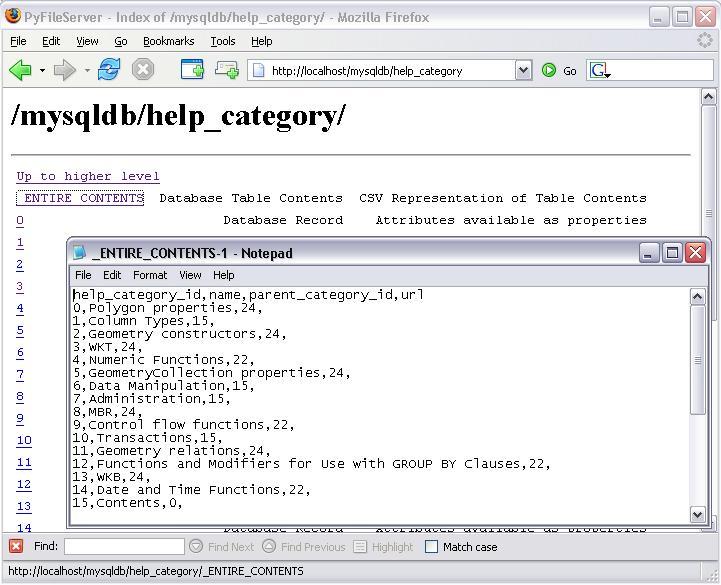
And so is live properties. cadaver doesnt show it of course, but the property namespace is "
Release coming up soon.
Tuesday, August 30, 2005
Database Resource Abstraction Layer
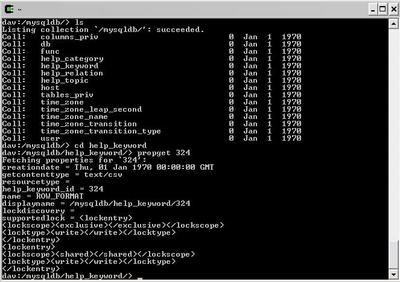
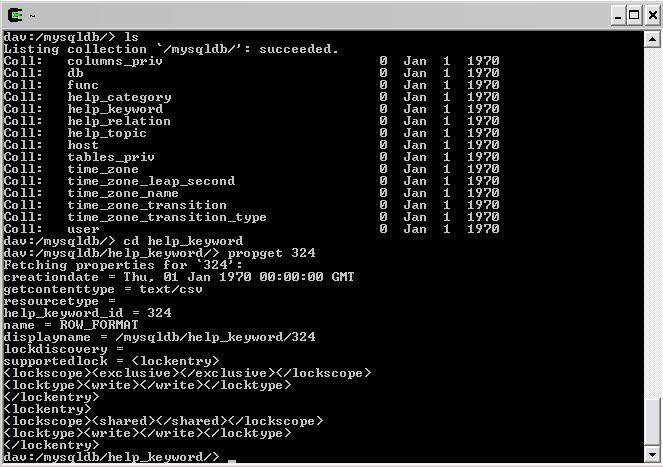
I've just put together a sample database abstraction layer to a MySQL database, for demonstration purposes:
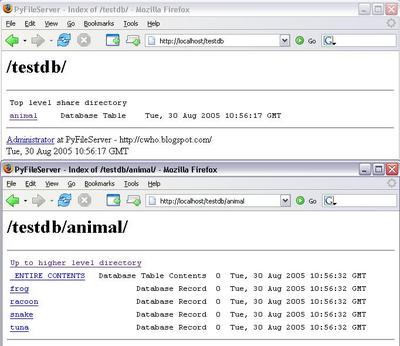
The idea (not all these features are working yet) is to allow read only access via the above methodology. _ENTIRE_CONTENTS will return a CSV representation of the data (assuming no large objects or equivalent). If the table has a SINGLE primary key, records will be listed as resources with names as those keys - these have no content but all attribute fields are available as live properties of these resources.
Trying to implement these highlighted some weaknesses in the server - it is too file oriented. Properties like modified/creation date may not mean anything to a record or table, and contentlength is a problem - there is no file size, so the only way to calculate the content length for a table.... is to retrieve ALL the content.
The solution here is to tweak the server to make these optional, such that if contentlength or modified date support is not provided, server will not use them (no last modified, no IF_(UN)MODIFIED_SINCE matching for example) or return the corresponding headers, and to support some other properties that were previously left out since they did not have too much to do with files, like getcontentlanguage.
Not all of this will appear by the SoC deadline, but most likely by mid-September (next release).
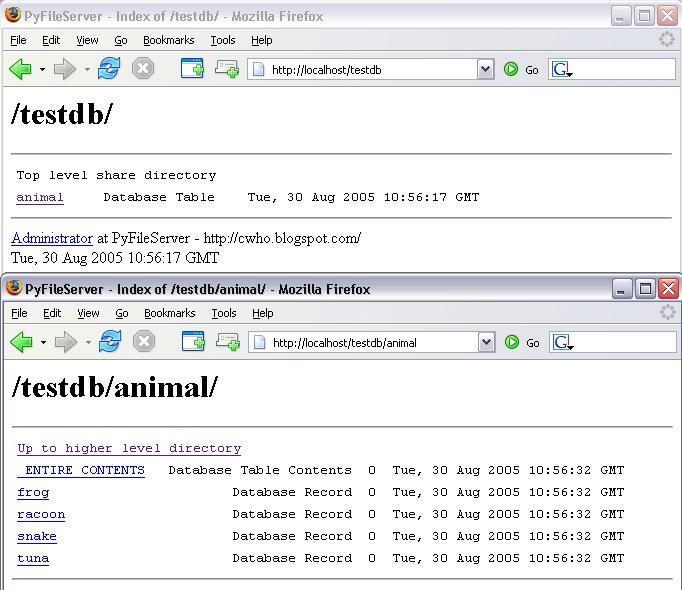
The idea (not all these features are working yet) is to allow read only access via the above methodology. _ENTIRE_CONTENTS will return a CSV representation of the data (assuming no large objects or equivalent). If the table has a SINGLE primary key, records will be listed as resources with names as those keys - these have no content but all attribute fields are available as live properties of these resources.
Trying to implement these highlighted some weaknesses in the server - it is too file oriented. Properties like modified/creation date may not mean anything to a record or table, and contentlength is a problem - there is no file size, so the only way to calculate the content length for a table.... is to retrieve ALL the content.
The solution here is to tweak the server to make these optional, such that if contentlength or modified date support is not provided, server will not use them (no last modified, no IF_(UN)MODIFIED_SINCE matching for example) or return the corresponding headers, and to support some other properties that were previously left out since they did not have too much to do with files, like getcontentlanguage.
Not all of this will appear by the SoC deadline, but most likely by mid-September (next release).
Monday, August 29, 2005
Release 0.2
Release 0.2:
+ Added resource abstraction layers. samples:
pyfileserver.fileabstraction.FilesystemAbstractionLayer and
pyfileserver.fileabstraction.ReadOnlyFilesystemAbstractionLayer
+ Removed etagprovider. Entity tags is now an aspect of the resource
abstraction layer.
+ Added interfaces pyfileserver.interfaces.*
+ cleaned up interface to lock library to make it more developer-friendly
+ More bug fixes as they are identified
Trying to make an example of using the resource layer to share resources other than files. As of this moment I am installing MySQL and reading up on MySQLdb module....
http://www.kitebird.com/articles/pydbapi.html
+ Added resource abstraction layers. samples:
pyfileserver.fileabstraction.FilesystemAbstractionLayer and
pyfileserver.fileabstraction.ReadOnlyFilesystemAbstractionLayer
+ Removed etagprovider. Entity tags is now an aspect of the resource
abstraction layer.
+ Added interfaces pyfileserver.interfaces.*
+ cleaned up interface to lock library to make it more developer-friendly
+ More bug fixes as they are identified
Trying to make an example of using the resource layer to share resources other than files. As of this moment I am installing MySQL and reading up on MySQLdb module....
http://www.kitebird.com/articles/pydbapi.html
Saturday, August 27, 2005
Release 0.1.3
Release 0.1.3:
Urgent fixes to some code in 0.1.2
Incorporated comments from code review except:
+ Architectural changes - dispatching
+ Additional information from exceptions (HTTPRequestException extended)
+ code in doMOVE / doCOPY (awaiting abstraction layer)
+ docstrings in websupportfuncs (awaiting abstraction layer)
More work on abstraction layer in progress...
Urgent fixes to some code in 0.1.2
Incorporated comments from code review except:
+ Architectural changes - dispatching
+ Additional information from exceptions (HTTPRequestException extended)
+ code in doMOVE / doCOPY (awaiting abstraction layer)
+ docstrings in websupportfuncs (awaiting abstraction layer)
More work on abstraction layer in progress...
Friday, August 26, 2005
Resource Abstraction Layer
Code is being refactored after an enlightening code review from my mentor -> thanks! :)
While that is being done (for the evaluation I think), I have also started halfway on a resource abstraction layer - that will allow the application to share resources from other sources (other than a filesystem).
A sample of the code below. I didn't want to make it too lengthy - but I've included path resolving and live properties (including etags and all the "dav" properties except the locking properties) as part of the abstraction layer, since it made sense to put them in. For example this could allow someone to share a database with tables as collections, records as resources and attributes as live properties of those resources. Thought I include the interface here as for comments.
All the code is commented (prefixed with #) since it seems blogger doesn't handle indentation well without something in front.
While that is being done (for the evaluation I think), I have also started halfway on a resource abstraction layer - that will allow the application to share resources from other sources (other than a filesystem).
A sample of the code below. I didn't want to make it too lengthy - but I've included path resolving and live properties (including etags and all the "dav" properties except the locking properties) as part of the abstraction layer, since it made sense to put them in. For example this could allow someone to share a database with tables as collections, records as resources and attributes as live properties of those resources. Thought I include the interface here as for comments.
All the code is commented (prefixed with #) since it seems blogger doesn't handle indentation well without something in front.
#class abstractionlayer(interface):
#
# def getResourceDescription(respath):
# """ returns a string containing resource description, e.g. "File", "Directory" """
#
# def getContentType(respath):
# """ returns the MIME Content-Type for resource: mimetypes.guess_type() """
#
# def getLastModified(respath):
# """ gets the Last Modified time (num of secs since epoch). Return 0 if not supported """
#
# def getContentLength(respath):
# """ gets the content length of the resource """
#
# def getEntityTag(respath):
# """ gets the entity tag for specified resource """
#
# def isCollection(respath):
# """ tests if this is a collection : os.path.isdir """
#
# def isResource(respath):
# """ tests if this is a non-collection resource : os.path.isfile """
#
# def exists(respath):
# """ tests if this resource exists : os.path.exists """
#
# def createCollection(respath):
# """ creates a collection : os.mkdir """
#
# def deleteCollection(respath):
# """ deletes a collection : os.rmdir """
#
# def openResourceForRead(respath):
# """ opens a resource for reading, returns stream """
#
# def openResourceForWrite(respath):
# """ opens a resource for writing, returns stream """
#
# def deleteResource(respath):
# """ deletes a resource : os.unlink """
#
# def copyResource(respath, destrespath):
# """ copies a resource : shutils.copy2 """
#
# def getContainingCollection(respath):
# """ returns the path of the collection containg the resource : os.path.dirname """
#
# def getContentsList(respath):
# """ returns a list of names of resources in this collection
# it is based on the assumption that names returned can be joinPath() with
# the specified path to form the path to the resource
# : os.listdir
# """
#
# def joinPath(rescollectionpath, resname):
# """ Joins the two path components intelligently : os.path.join """
#
# def splitPath(respath):
# """ Splits a path returning a tuple (containg collection path, # resource name) : os.path.split
# """
#
# def getProperty(respath, propertyname, propertyns):
# """ returns property value for resource. This should implement all the required
# webdav properties except locking properties
# """
#
# def isPropertySupported(respath, propertyname, propertyns):
# """ tests if the specified property is a live property supported. If it is not
# supported, the application will look for it in the dead properties library
# """
#
# def resolvePath(resheadpath, urlelementlist):
# """ resolves the given url sequence to a path. Example:
# the directory c:\Test was shared as http://localhost/testing/.
# Then user accessing http://localhost/testing/dir1/dir2/file1.txt
# will require resolvePath to return a valid path to file1.txt from
# resolvePath('c:\Test', ['dir1','dir2','file1.txt'].
#
# An exception exiting this function may result in return of a 404 File Not Found
# """
Tuesday, August 23, 2005
Release 0.1.2
Release 0.1.2:
+ Minor fixes to Tutorial
+ Added windowsdomaincontroller under pyfileserver.addons
+ Added Addons documentation section
The windowsdomaincontroller allows the user to authenticate against a Windows NT domain or a local computer, requires NT or beyond (2000, XP, 2003, etc).
This class requires Mark Hammond's Win32 extensions for Python:
http://starship.python.net/crew/mhammond/win32/Downloads.html
http://sourceforge.net/projects/pywin32/
Information on Win32 network authentication was from the following resources:
http://ejabberd.jabber.ru/node/55
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/81402
+ Minor fixes to Tutorial
+ Added windowsdomaincontroller under pyfileserver.addons
+ Added Addons documentation section
The windowsdomaincontroller allows the user to authenticate against a Windows NT domain or a local computer, requires NT or beyond (2000, XP, 2003, etc).
This class requires Mark Hammond's Win32 extensions for Python:
http://starship.python.net/crew/mhammond/win32/Downloads.html
http://sourceforge.net/projects/pywin32/
Information on Win32 network authentication was from the following resources:
http://ejabberd.jabber.ru/node/55
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/81402
Friday, August 19, 2005
Release 0.1.1
Just released PyFileServer 0.1.1
+ Fixed up setup.py
+ Added Tutorial to documentation
+ Now sends 401 for invalid auth request instead of 404
+ disable realm checking - partial hotfix for WinXP webdav redirector
remembering auth details for the same user using it for different
realms (since it is the same host)
+ Other misc bugs.
+ Fixed up setup.py
+ Added Tutorial to documentation
+ Now sends 401 for invalid auth request instead of 404
+ disable realm checking - partial hotfix for WinXP webdav redirector
remembering auth details for the same user using it for different
realms (since it is the same host)
+ Other misc bugs.
Wednesday, August 17, 2005
What it should have been
I was using the term
In summary,
dbm previously when I meant standard database connection, which I had in mind the SimpleSessionServer from WSGIUtils. It didn't really hit me till right now that shelve is implemented over dbm, and anyway SimpleSessionServer uses sockets to communicate with a anydbm repository.
In summary,
shelve already uses dbm (the standard db interface). I really pulled a Charlie Gordon on this one.
Tuesday, August 16, 2005
Week 7
Progress In Project
Following the release of 0.1, pace of development has slowed down a bit. I ran out of items sitting on the list that could just be done, the others require some research...
These days, I am (in this order of priorities):
+ Reading up and experimenting with
+ Attempting to debug inconsistencies with authentication that WinXP Network Places has with the server. Not having too much luck with this, there must be something I am missing.
+ Getting setup tools to use
Google Code Jam
Like any enthusastic coder, of course I signed up for the Google Code Jam :). I tried out practice set 1, and was having trouble understanding their solution to the DiskDefrag problem (given a number of discontiguous files in a set of blocks simulating a filesystem, compute the minimum number of moves/block moving operations required to have all files in contiguous order.) The solution uses some sort of dynamic programming, but the mathematics/logic is still boiling around in my mind.
I tried a different approach by generating all valid contiguous ordered file position combinations in the filesystem and looking for the minimum number of moves from the current position to one of these valid positions. For max of 12 files and 100 block size this does not appear to be overwhelmingly intensive (but does not scale well). It worked for several test cases but running the full test shows it does not run (expectedly) within a previously-unmentioned 2 seconds limit for some test cases. Back to the drawing board.
MOBA
For anyone who was puzzled by one of the comments of the previous post, MOBA = My Own BS Algorithm, commonly refering to self-known or self-invented hacks. It is no coincidence that "a MOBA" (also known as AMOEBA) is a large single cellular organism, just like unmodular code.
I'll let users be the judge if MOBA is in the code. :)
Following the release of 0.1, pace of development has slowed down a bit. I ran out of items sitting on the list that could just be done, the others require some research...
These days, I am (in this order of priorities):
+ Reading up and experimenting with
dbm (to try and package a database backed lock and poperties library with the server other than the existing shelve based libraries)
+ Attempting to debug inconsistencies with authentication that WinXP Network Places has with the server. Not having too much luck with this, there must be something I am missing.
+ Getting setup tools to use
install_requires properly to download and install PyXML. Right now it does not find PyXML over PyPI, so instead I replaced it with a manual check and a print message that PyXML is required.
Google Code Jam
Like any enthusastic coder, of course I signed up for the Google Code Jam :). I tried out practice set 1, and was having trouble understanding their solution to the DiskDefrag problem (given a number of discontiguous files in a set of blocks simulating a filesystem, compute the minimum number of moves/block moving operations required to have all files in contiguous order.) The solution uses some sort of dynamic programming, but the mathematics/logic is still boiling around in my mind.
I tried a different approach by generating all valid contiguous ordered file position combinations in the filesystem and looking for the minimum number of moves from the current position to one of these valid positions. For max of 12 files and 100 block size this does not appear to be overwhelmingly intensive (but does not scale well). It worked for several test cases but running the full test shows it does not run (expectedly) within a previously-unmentioned 2 seconds limit for some test cases. Back to the drawing board.
MOBA
For anyone who was puzzled by one of the comments of the previous post, MOBA = My Own BS Algorithm, commonly refering to self-known or self-invented hacks. It is no coincidence that "a MOBA" (also known as AMOEBA) is a large single cellular organism, just like unmodular code.
I'll let users be the judge if MOBA is in the code. :)
Wednesday, August 10, 2005
File Release
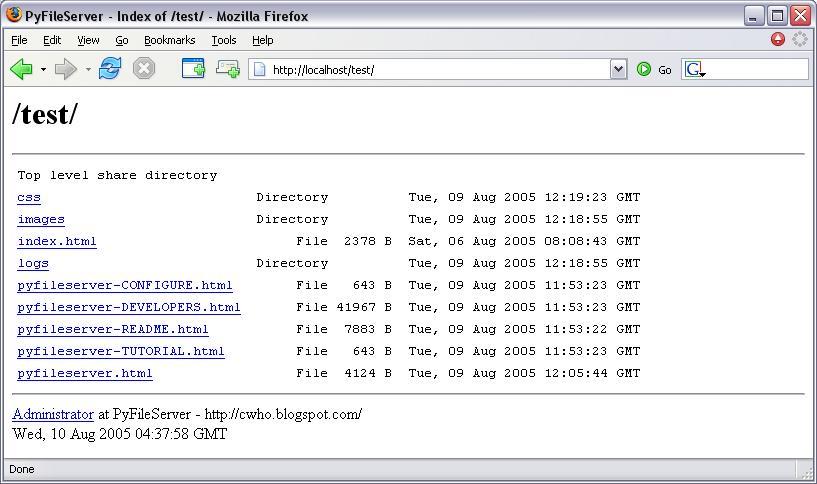
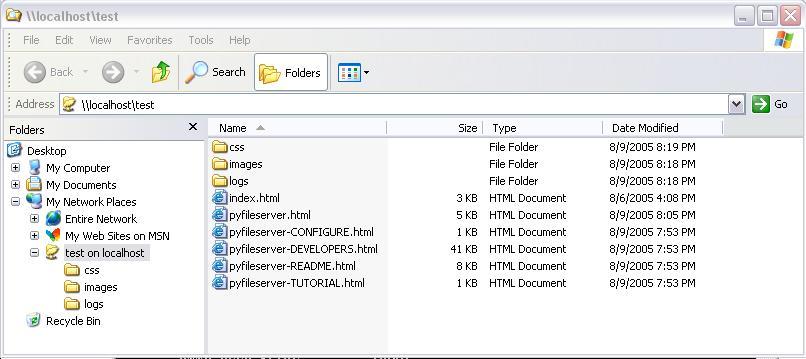
I just released version 0.1.
XP support, despite what you see here, is not too perfect yet. Its buggy in a sense, XP Network Places appears to remember your successful authentication details the first time, and then either submit those details for a different user/realm, or refuse to accept new details (request header monitoring shows that it does not submit the authentication header for the new details).
Working out those details... and also picking up misc bugs around the place.
Monday, August 08, 2005
Week 6
WebDAV functionality
Locks - Done. Working with both litmus and DAVExplorer. DAVExplorer tends to be a tad buggy in this respect. After a while it seems to forget that the resource is locked and does not submit a If header - has to be 'reminded' by locking/unlocking.
XP WebDAV support - works. Earlier today I was able to mount it on my Network Places, browse the filespace, read files, copy files from local drive onto the filespace, create folders, move/copy files within the filespace, delete files. Will continue to play with it. There does not appear to be a locking functionality.
cadaver - will be tested soon, but I don't really expect any major hiccups.
What's next?
Initial File Release (I just want to release something). And then:
A lot of cleaning code:
+ Setting a proper verbose option and removing all the out-of-place-for-debugging print statements
+ I need to figure out how logging is used (
+ Catch "Software Caused Connection Abort" exceptions and stop them from spamming the screen and drowning real exceptions. They are thrown when the client closes the connection even before the whole response is transmitted, since the response code is the first thing it gets - and needs. Quite the literal slamming down the phone before the other side has finished his piece, but its also quite common. :)
Better structuring:
+ Cleaning up the locks manager interface. Right now its a mess of functions defined and named at-hoc.
+ If time permits, I like to make another set of locksmanager, propertymanager, domaincontroller, this time based on a database (probably
Locks - Done. Working with both litmus and DAVExplorer. DAVExplorer tends to be a tad buggy in this respect. After a while it seems to forget that the resource is locked and does not submit a If header - has to be 'reminded' by locking/unlocking.
XP WebDAV support - works. Earlier today I was able to mount it on my Network Places, browse the filespace, read files, copy files from local drive onto the filespace, create folders, move/copy files within the filespace, delete files. Will continue to play with it. There does not appear to be a locking functionality.
cadaver - will be tested soon, but I don't really expect any major hiccups.
What's next?
Initial File Release (I just want to release something). And then:
A lot of cleaning code:
+ Setting a proper verbose option and removing all the out-of-place-for-debugging print statements
+ I need to figure out how logging is used (
logging the standard module), and if it is something that should be standardize within my code
+ Catch "Software Caused Connection Abort" exceptions and stop them from spamming the screen and drowning real exceptions. They are thrown when the client closes the connection even before the whole response is transmitted, since the response code is the first thing it gets - and needs. Quite the literal slamming down the phone before the other side has finished his piece, but its also quite common. :)
Better structuring:
+ Cleaning up the locks manager interface. Right now its a mess of functions defined and named at-hoc.
+ If time permits, I like to make another set of locksmanager, propertymanager, domaincontroller, this time based on a database (probably
dbm). I am slightly unhappy with the performance and usability of the existing shelve components
Saturday, August 06, 2005
Week 5: Ends
So ends Week 5.
Locks
Posted on the litmus mailing list for some strange results I was getting, seems like I got the locks/If-header handling part wrong (again!). Thanks to Julian Reschke who has been answering a lot of my queries on the specification on litmus@webdav.org and w3c-dist-auth@w3.org lists
Reworking....
Testing
Win XP Network Places still refuses to recognize the webdav server, but thankfully I googled first before jumping in with the gearbox, there is a thread and some resources that address this problem in depth:
http://lists.w3.org/Archives/Public/w3c-dist-auth/2002JanMar/0064.html
http://greenbytes.de/tech/webdav/webdav-redirector-list.html
Documentation
Have the modules moderately documented and cooking up some standalone documentation.
Distribution
At my mentor's suggestion I looked up setuptools http://peak.telecommunity.com/DevCenter/setuptools, which is much easier to use than distutils. I like to think I got a working setup.py cooked up, but I have not tested it yet.
CVS and SVN
In miscellaneous refactoring and renaming to be compliant with PEP-8, I had to rename some of my files and directories to fully lowercase. While CVS and SVN both do not allow case only renames, SVN at least has a standard workaround. SVN is fully updated with the latest code.
All the CVS workarounds that I managed to google did not work out, so I am abandoning the CVS repository. The current version has the tree wiped and CVS anonymous access has been disabled.
Locks
Posted on the litmus mailing list for some strange results I was getting, seems like I got the locks/If-header handling part wrong (again!). Thanks to Julian Reschke who has been answering a lot of my queries on the specification on litmus@webdav.org and w3c-dist-auth@w3.org lists
Reworking....
Testing
Win XP Network Places still refuses to recognize the webdav server, but thankfully I googled first before jumping in with the gearbox, there is a thread and some resources that address this problem in depth:
http://lists.w3.org/Archives/Public/w3c-dist-auth/2002JanMar/0064.html
http://greenbytes.de/tech/webdav/webdav-redirector-list.html
Documentation
Have the modules moderately documented and cooking up some standalone documentation.
Distribution
At my mentor's suggestion I looked up setuptools http://peak.telecommunity.com/DevCenter/setuptools, which is much easier to use than distutils. I like to think I got a working setup.py cooked up, but I have not tested it yet.
CVS and SVN
In miscellaneous refactoring and renaming to be compliant with PEP-8, I had to rename some of my files and directories to fully lowercase. While CVS and SVN both do not allow case only renames, SVN at least has a standard workaround. SVN is fully updated with the latest code.
All the CVS workarounds that I managed to google did not work out, so I am abandoning the CVS repository. The current version has the tree wiped and CVS anonymous access has been disabled.
Wednesday, August 03, 2005
Wednesday
Today was less productive on coding, starting preparation on other portions.
+ Managed to get a project page up. This one wouldnt win any web design awards tho. http://pyfilesync.berlios.de/
+ Did misc administration, categorizing and feature selection/cleanup of the "pyfilesync" project on BerliOS proper. Finally managed to get anonymous SVN access working, the SVN feature has to be enabled (only CVS is enabled by default) for the project. So.... I can create an SVN repository, populate it and share its contents with team members with the SVN feature disabled, but anonymous SVN access, now that requires enabling the feature.... intuitive?
+ Looking at File Modules and Releases on BerliOS next
+ Reading on setuptools and reStruturedText for packaging and documentation
+ Testing and debugging (still trying to get DAVExplorer to work with locks)
University starts next week, just chose my modules today, and I am already planning on skipping classes :)
+ Managed to get a project page up. This one wouldnt win any web design awards tho. http://pyfilesync.berlios.de/
+ Did misc administration, categorizing and feature selection/cleanup of the "pyfilesync" project on BerliOS proper. Finally managed to get anonymous SVN access working, the SVN feature has to be enabled (only CVS is enabled by default) for the project. So.... I can create an SVN repository, populate it and share its contents with team members with the SVN feature disabled, but anonymous SVN access, now that requires enabling the feature.... intuitive?
+ Looking at File Modules and Releases on BerliOS next
+ Reading on setuptools and reStruturedText for packaging and documentation
+ Testing and debugging (still trying to get DAVExplorer to work with locks)
University starts next week, just chose my modules today, and I am already planning on skipping classes :)
Tuesday, August 02, 2005
Operation Atomcity
This is the second blog post for today, but it really belongs as a separate topic.
This just hit me while I was mucking around finalizing the locking code. There might be an issue with concurrent requests, since the webDAV is running off the file system directly.
For example, if a file is constantly GETed, there will be no way to DELETE it since delete will fail because the file is always open for reading for the GET processes. Denial of Delete Service attack? There are potential clashes like this that could cause methods like MOVE or COPY to fail, even if the client does all the proper LOCKing beforehand.
The simple fix is to put a threading.RLock over all the operations, so that only one operation is being done, and done to completion before the next one comes in, but this really limits the server to a pseudo -single thread- operation, which is really means no concurrency support. The complex way would be to define locks such that operations can only be carried out concurrently if they do not conflict, defined loosely as if the two requests are not direct ancestor/descendants of each other in the file structure (since operations can have Depth == infinity).
I am just wondering if this level of robustness is required here......
This just hit me while I was mucking around finalizing the locking code. There might be an issue with concurrent requests, since the webDAV is running off the file system directly.
For example, if a file is constantly GETed, there will be no way to DELETE it since delete will fail because the file is always open for reading for the GET processes. Denial of Delete Service attack? There are potential clashes like this that could cause methods like MOVE or COPY to fail, even if the client does all the proper LOCKing beforehand.
The simple fix is to put a threading.RLock over all the operations, so that only one operation is being done, and done to completion before the next one comes in, but this really limits the server to a pseudo -single thread- operation, which is really means no concurrency support. The complex way would be to define locks such that operations can only be carried out concurrently if they do not conflict, defined loosely as if the two requests are not direct ancestor/descendants of each other in the file structure (since operations can have Depth == infinity).
I am just wondering if this level of robustness is required here......
The server is done
The webDAV server is done! I finished locking today, ran through the whole series of neon-litmus tests today and everything fell through:
cwho@CHIMAERA /cygdrive/c/Soc/litmus-0.10.2/litmus-0.10.2
$ litmus http://localhost:8080/test/ tester tester
-> running `basic':
...
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
...
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
...
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
-> running `locks':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. precond............... pass
4. init_locks............ pass
5. put................... pass
6. lock_excl............. pass
7. discover.............. pass
8. refresh............... pass
9. notowner_modify....... pass
10. notowner_lock......... pass
11. owner_modify.......... pass
12. notowner_modify....... pass
13. notowner_lock......... pass
14. copy.................. pass
15. cond_put.............. pass
16. fail_cond_put......... pass
17. cond_put_with_not..... pass
18. cond_put_corrupt_token pass
19. complex_cond_put...... pass
20. fail_complex_cond_put. pass
21. unlock................ pass
22. lock_shared........... pass
23. notowner_modify....... pass
24. notowner_lock......... pass
25. owner_modify.......... pass
26. double_sharedlock..... pass
27. notowner_modify....... pass
28. notowner_lock......... pass
29. unlock................ pass
30. prep_collection....... pass
31. lock_collection....... pass
32. owner_modify.......... pass
33. notowner_modify....... pass
34. refresh............... pass
35. indirect_refresh...... pass
36. unlock................ pass
37. finish................ pass
<- summary for `locks': of 38 tests run: 38 passed, 0 failed. 100.0%
-> running `http':
0. init.................. pass
1. begin................. pass
2. expect100............. pass
3. finish................ pass
<- summary for `http': of 4 tests run: 4 passed, 0 failed. 100.0%
I will continue testing with standard webDAV clients:
+ DAVExplorer 0.91 (Java-based)
Did some testing, the normal operations work but locking still needs working out. More debugging...
+ Cadaver 0.22.2 (just managed to compile it over cygwin)
Also in the priority queue are:
+ packaging and layout
+ conversion of tab-indents to 4-indent
+ misc refactoring
Some accumulated low priority TODOs throughout:
+ Figure out what the warning for litmus: "WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe" is
+ Gzip support for Content-Encoding (a challenge to support with Content-Ranges)
+ More support for null resource locking -> this is slightly hard to do since I have been relying on the file system itself as the arbiter of what is there and what is not.
+ Encryption -> SSL support would probably be a property of the web server itself.
cwho@CHIMAERA /cygdrive/c/Soc/litmus-0.10.2/litmus-0.10.2
$ litmus http://localhost:8080/test/ tester tester
-> running `basic':
...
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
...
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
...
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
-> running `locks':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. precond............... pass
4. init_locks............ pass
5. put................... pass
6. lock_excl............. pass
7. discover.............. pass
8. refresh............... pass
9. notowner_modify....... pass
10. notowner_lock......... pass
11. owner_modify.......... pass
12. notowner_modify....... pass
13. notowner_lock......... pass
14. copy.................. pass
15. cond_put.............. pass
16. fail_cond_put......... pass
17. cond_put_with_not..... pass
18. cond_put_corrupt_token pass
19. complex_cond_put...... pass
20. fail_complex_cond_put. pass
21. unlock................ pass
22. lock_shared........... pass
23. notowner_modify....... pass
24. notowner_lock......... pass
25. owner_modify.......... pass
26. double_sharedlock..... pass
27. notowner_modify....... pass
28. notowner_lock......... pass
29. unlock................ pass
30. prep_collection....... pass
31. lock_collection....... pass
32. owner_modify.......... pass
33. notowner_modify....... pass
34. refresh............... pass
35. indirect_refresh...... pass
36. unlock................ pass
37. finish................ pass
<- summary for `locks': of 38 tests run: 38 passed, 0 failed. 100.0%
-> running `http':
0. init.................. pass
1. begin................. pass
2. expect100............. pass
3. finish................ pass
<- summary for `http': of 4 tests run: 4 passed, 0 failed. 100.0%
I will continue testing with standard webDAV clients:
+ DAVExplorer 0.91 (Java-based)
Did some testing, the normal operations work but locking still needs working out. More debugging...
+ Cadaver 0.22.2 (just managed to compile it over cygwin)
Also in the priority queue are:
+ packaging and layout
+ conversion of tab-indents to 4-indent
+ misc refactoring
Some accumulated low priority TODOs throughout:
+ Figure out what the warning for litmus: "WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe" is
+ Gzip support for Content-Encoding (a challenge to support with Content-Ranges)
+ More support for null resource locking -> this is slightly hard to do since I have been relying on the file system itself as the arbiter of what is there and what is not.
+ Encryption -> SSL support would probably be a property of the web server itself.
Monday, August 01, 2005
Week 5: Locks
Locks got off to a good start.
Locks Managing
Unlike dead properties, locks was slightly more complex to model as a locks over it.
What I did was to store the information in a slightly redundant way. Each lock stored which urls it locked, and each url stored which locks was applicable over it.
Since
where
This does mean no support for concurrency - only one writing Lock operation can be performed at any one time.
Test Status
Is too ugly to put on the blog at the moment. Let's just say that I got what I want for locks coded, except for write locks over null resources and adding new resources to existing collection locks. But there is a lot of debugging to be done.
One big realization coming out of this is how important tests are. Initially I was writing code that I knew worked and letting the tests verify what I knew (something like a rubberstamp), but as the project goes along I am increasingly relying on tests to catch what I should have caught in coding.
One thing for sure, I could not have made such progress without the litmus test suite. Having to write out, code and conduct the tests alone would have taken me about as much time as I spend on the server.
Locks Managing
Unlike dead properties, locks was slightly more complex to model as a
shelve dict structure, since its really two structures - locks and urls. Each lock is applied over a number of urls, and one url could have several What I did was to store the information in a slightly redundant way. Each lock stored which urls it locked, and each url stored which locks was applicable over it.
Since
shelve sub-dicts (that is, dictionaries and other data structures that are themselves value elements within the shelve dict) are retrieved, manipulated in memory and then written back to the repository on sync, this duplicated structure meant that two concurrent lock operations over the same resource could make the two sub-dicts inconsistent with each other by writing the wrong structure at the wrong time. What I did was to use threading such that:
def writinglockoperation(self, args):
...self._write_lock.acquire(blocking=True)
...try:
......doStuff...
...finally:
......self._dict.sync()
......self._write_lock.release()
where
self._dict is the shelve dict and self._write_lock is a threading.RLockThis does mean no support for concurrency - only one writing Lock operation can be performed at any one time.
Test Status
Is too ugly to put on the blog at the moment. Let's just say that I got what I want for locks coded, except for write locks over null resources and adding new resources to existing collection locks. But there is a lot of debugging to be done.
One big realization coming out of this is how important tests are. Initially I was writing code that I knew worked and letting the tests verify what I knew (something like a rubberstamp), but as the project goes along I am increasingly relying on tests to catch what I should have caught in coding.
One thing for sure, I could not have made such progress without the litmus test suite. Having to write out, code and conduct the tests alone would have taken me about as much time as I spend on the server.
Saturday, July 30, 2005
Week 4 was kidnapped by the Martians
Hi,
Just dropping a message to the blog here (ping? pong!). I said I was going to spend less time on the project this week, turns out I spent none :| Exams didn't go too good either.
In the coming week 5, working on LOCKS. I hope I am still making good time on this project.
Just dropping a message to the blog here (ping? pong!). I said I was going to spend less time on the project this week, turns out I spent none :| Exams didn't go too good either.
In the coming week 5, working on LOCKS. I hope I am still making good time on this project.
Saturday, July 23, 2005
Class 1 WebDAV Server
Failed to finish what I wanted to finish yesterday, thanks to some amazing careless errors that neon-litmus deftly caught in COPY, MOVE and PROPFIND, PROPPATCH. Most of these were mistakes and places that I missed in the spec.
Had some troubles with Unicode. I forgot that encoding a high-unicode string to UTF-8 and then concatenating that string with some ascii-encodable "normal" unicode string *changes* the whole thing back to unicode, and was surprised it was still throwing errors after I encoded it. But its working now.
Test Status
I will spend less time on the project for a week - thanks to summer course exams, but right now I have a Class 1 WebDAV server, with only locking lacking (admittedly that will take a bit of work and affect all other methods).
The code has been updated on SVN and CVS. Naming convention is there but script to change to 4-indent is still on the TODO list.
-> running `basic':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. put_get............... pass
4. put_get_utf8_segment.. pass
5. mkcol_over_plain...... pass
6. delete................ pass
7. delete_null........... pass
8. delete_fragment....... WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe ...................... pass (with 1 warning)
9. mkcol................. pass
10. mkcol_again........... pass
11. delete_coll........... pass
12. mkcol_no_parent....... pass
13. mkcol_with_body....... pass
14. finish................ pass
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
0. init.................. pass
1. begin................. pass
2. copy_init............. pass
3. copy_simple........... pass
4. copy_overwrite........ pass
5. copy_nodestcoll....... pass
6. copy_cleanup.......... pass
7. copy_coll............. pass
8. move.................. pass
9. move_coll............. pass
10. move_cleanup.......... pass
11. finish................ pass
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
0. init.................. pass
1. begin................. pass
2. propfind_invalid...... pass
3. propfind_invalid2..... pass
4. propfind_d0........... pass
5. propinit.............. pass
6. propset............... pass
7. propget............... pass
8. propextended.......... pass
9. propmove.............. pass
10. propget............... pass
11. propdeletes........... pass
12. propget............... pass
13. propreplace........... pass
14. propget............... pass
15. propnullns............ pass
16. propget............... pass
17. prophighunicode....... pass
18. propget............... pass
19. propvalnspace......... pass
20. propwformed........... pass
21. propinit.............. pass
22. propmanyns............ pass
23. propget............... pass
24. propcleanup........... pass
25. finish................ pass
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
there's still lock and http test sets to go. I cannot skip lock and go straight to http, so guess that will have to wait.
Had some troubles with Unicode. I forgot that encoding a high-unicode string to UTF-8 and then concatenating that string with some ascii-encodable "normal" unicode string *changes* the whole thing back to unicode, and was surprised it was still throwing errors after I encoded it. But its working now.
Test Status
I will spend less time on the project for a week - thanks to summer course exams, but right now I have a Class 1 WebDAV server, with only locking lacking (admittedly that will take a bit of work and affect all other methods).
The code has been updated on SVN and CVS. Naming convention is there but script to change to 4-indent is still on the TODO list.
-> running `basic':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. put_get............... pass
4. put_get_utf8_segment.. pass
5. mkcol_over_plain...... pass
6. delete................ pass
7. delete_null........... pass
8. delete_fragment....... WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe ...................... pass (with 1 warning)
9. mkcol................. pass
10. mkcol_again........... pass
11. delete_coll........... pass
12. mkcol_no_parent....... pass
13. mkcol_with_body....... pass
14. finish................ pass
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
-> running `copymove':
0. init.................. pass
1. begin................. pass
2. copy_init............. pass
3. copy_simple........... pass
4. copy_overwrite........ pass
5. copy_nodestcoll....... pass
6. copy_cleanup.......... pass
7. copy_coll............. pass
8. move.................. pass
9. move_coll............. pass
10. move_cleanup.......... pass
11. finish................ pass
<- summary for `copymove': of 12 tests run: 12 passed, 0 failed. 100.0%
-> running `props':
0. init.................. pass
1. begin................. pass
2. propfind_invalid...... pass
3. propfind_invalid2..... pass
4. propfind_d0........... pass
5. propinit.............. pass
6. propset............... pass
7. propget............... pass
8. propextended.......... pass
9. propmove.............. pass
10. propget............... pass
11. propdeletes........... pass
12. propget............... pass
13. propreplace........... pass
14. propget............... pass
15. propnullns............ pass
16. propget............... pass
17. prophighunicode....... pass
18. propget............... pass
19. propvalnspace......... pass
20. propwformed........... pass
21. propinit.............. pass
22. propmanyns............ pass
23. propget............... pass
24. propcleanup........... pass
25. finish................ pass
<- summary for `props': of 26 tests run: 26 passed, 0 failed. 100.0%
there's still lock and http test sets to go. I cannot skip lock and go straight to http, so guess that will have to wait.
Friday, July 22, 2005
Galore of Errors
Yesterday I finished work on the MOVE and COPY commands and was ready to start on testing this application as integrated. Only the LOCK mechanisms are lacking and I will implement that, prefering to do a midway test. The litmus library http://www.webdav.org/neon/litmus/ was perfect for this. I installed and compiled it over cygwin.
Extending the server:
After several failures on the first test (MKCOL) and some telnetting of my own, I realise that paster was using wsgiServer, based off SimpleHTTPHandler, which filters off all the requests except HEAD, GET, PUT. There was not much choice but to duplicate a paste server plug-in that allowed these methods. I copied code off wsgiServer and wsgiutils_server, and borrowed a pattern from http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/307618 , which uses __getattr__ to allow me to specify a list of supported methods rather than define a separate method to do the same thing - pass request to application. It works now.
Reading the request body
The next thing I found was that reading off environ['wsgi.input'] would end up blocking, since it is a stream that is still open. I will have to check the Content Length variable to get the number of bytes to read, but is there another option to not block_read, in case Content Length is not given? My unfixed code is:
Catching Iterator Code Exceptions
Some of the exceptions thrown were not being caught by my error processing middleware, it was because some of my sub-apps return a iterator object, which is iterated out of the scope of my error processor. for example:
From my old functional perspective, B() should be able to catch the exception in C(), since C is within its scope. In reality, when B is executed, B returns C() immediately as a generator/iterator object, without executing C() itself. B then exits its scope. When A tries to use the iterator object returned, C() runs and throws the exception on A which thought it was protected. So instead I went to look at paste.errormiddleware on how it was catching iterator exceptions and implemented it accordingly.
Current Test Status
-> running `basic':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. put_get............... pass
4. put_get_utf8_segment.. pass
5. mkcol_over_plain...... pass
6. delete................ pass
7. delete_null........... pass
8. delete_fragment....... WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe...................... pass (with 1 warning)
9. mkcol................. pass
10. mkcol_again........... pass
11. delete_coll........... pass
12. mkcol_no_parent....... pass
13. mkcol_with_body....... pass
14. finish................ pass
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
This is the basic test set, following which are sets for copymove, props, locks and http. As of this moment I am still sorting out the copymove errors identified.
Extending the server:
After several failures on the first test (MKCOL) and some telnetting of my own, I realise that paster was using wsgiServer, based off SimpleHTTPHandler, which filters off all the requests except HEAD, GET, PUT. There was not much choice but to duplicate a paste server plug-in that allowed these methods. I copied code off wsgiServer and wsgiutils_server, and borrowed a pattern from http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/307618 , which uses __getattr__ to allow me to specify a list of supported methods rather than define a separate method to do the same thing - pass request to application. It works now.
Reading the request body
The next thing I found was that reading off environ['wsgi.input'] would end up blocking, since it is a stream that is still open. I will have to check the Content Length variable to get the number of bytes to read, but is there another option to not block_read, in case Content Length is not given? My unfixed code is:
requestbody = ''
if 'wsgi.input' in environ:
....inputstream = environ['wsgi.input']
....readbuffer = inputstream.read(BUF_SIZE)
....while len(readbuffer) != 0:
........requestbody = requestbody + readbuffer
........readbuffer = inputstream.read(BUF_SIZE)
Catching Iterator Code Exceptions
Some of the exceptions thrown were not being caught by my error processing middleware, it was because some of my sub-apps return a iterator object, which is iterated out of the scope of my error processor. for example:
def A():
....for v in iter(B()):
........print v
def B():
....try:
........return C()
....except:
........return ['exception']
def C():
....raise Exception
....yield '1'
....yield '2'
From my old functional perspective, B() should be able to catch the exception in C(), since C is within its scope. In reality, when B is executed, B returns C() immediately as a generator/iterator object, without executing C() itself. B then exits its scope. When A tries to use the iterator object returned, C() runs and throws the exception on A which thought it was protected. So instead I went to look at paste.errormiddleware on how it was catching iterator exceptions and implemented it accordingly.
Current Test Status
-> running `basic':
0. init.................. pass
1. begin................. pass
2. options............... pass
3. put_get............... pass
4. put_get_utf8_segment.. pass
5. mkcol_over_plain...... pass
6. delete................ pass
7. delete_null........... pass
8. delete_fragment....... WARNING: DELETE removed collection resource with Request-URI including fragment; unsafe...................... pass (with 1 warning)
9. mkcol................. pass
10. mkcol_again........... pass
11. delete_coll........... pass
12. mkcol_no_parent....... pass
13. mkcol_with_body....... pass
14. finish................ pass
<- summary for `basic': of 15 tests run: 15 passed, 0 failed. 100.0%
-> 1 warning was issued.
This is the basic test set, following which are sets for copymove, props, locks and http. As of this moment I am still sorting out the copymove errors identified.
Wednesday, July 20, 2005
Update
Refactoring was the order of the day, including getting rid of some out-of-the-way customizations like POSTing to get directory lists. Moved things around and cleaned it up, essentially
PROPPATCH is also working, even if the property value is specified in XML substructures.
Added support for the If header in webDAV. Improved support for the HTTP range header to consolidate multiple-overlapping ranges into a single range - left over from TODO.
Question: General confusion over whether the If header should apply to PROPFIND, and whether the HTTP If-Match/If-Modified-Since conditionals should apply to PROPFIND, and how If and HTTP Ifs would apply to the webDAV methods if multiple files are involved.
I have posted to the W3C Dist Authoring working group to ask for clarifications.
This week code will flow slightly slower since the summer course is holding exams (and I am cramming for it)
PROPPATCH is also working, even if the property value is specified in XML substructures.
Added support for the If header in webDAV. Improved support for the HTTP range header to consolidate multiple-overlapping ranges into a single range - left over from TODO.
Question: General confusion over whether the If header should apply to PROPFIND, and whether the HTTP If-Match/If-Modified-Since conditionals should apply to PROPFIND, and how If and HTTP Ifs would apply to the webDAV methods if multiple files are involved.
I have posted to the W3C Dist Authoring working group to ask for clarifications.
This week code will flow slightly slower since the summer course is holding exams (and I am cramming for it)
Tuesday, July 19, 2005
Third Week Starts
Property Library
Spent some time yesterday looking at shelve and related modules for a persistent store of dead properties and locks. I put together a property library using shelve, but had some problems placing the initialization and saving of the library to persistent store as the server tends to result in multiple initialization of the application, and no fixed deallocator (atexit does not work since os_exit() is used for restarting).
Current implementation is a library to initialies on first request (using threading to protect from concurrent initializations) and syncs after every write. The file lock should be released automatically when the process terminates.
XML, PROPFIND
Installed PyXML and started work on PROPFIND, which is working. Will link it to the main application once PROPPATCH is also working. Depth support is present.
CVS / SVN
Both repositories are up to date. I modified the top level directory name of the CVS repository to refresh it. "thirdparty" probably should be removed, it contains code that was referenced but not actually included.
Spent some time yesterday looking at shelve and related modules for a persistent store of dead properties and locks. I put together a property library using shelve, but had some problems placing the initialization and saving of the library to persistent store as the server tends to result in multiple initialization of the application, and no fixed deallocator (atexit does not work since os_exit() is used for restarting).
Current implementation is a library to initialies on first request (using threading to protect from concurrent initializations) and syncs after every write. The file lock should be released automatically when the process terminates.
XML, PROPFIND
Installed PyXML and started work on PROPFIND, which is working. Will link it to the main application once PROPPATCH is also working. Depth support is present.
CVS / SVN
Both repositories are up to date. I modified the top level directory name of the CVS repository to refresh it. "thirdparty" probably should be removed, it contains code that was referenced but not actually included.
Saturday, July 16, 2005
Weekend again!
Week 2 is over and coding is progressing. Hope I am going along at a reasonable speed at least.
Thanks to my mentor who pointed out that webDAV servers do support Basic. The spec mentions that webDAV servers should support Digest but I missed the fact that they can also support Basic (especially over SSL). I have done both basic and digest, right now it is standalone module (in httpauthentication.py) but digest would be a great addition to paste.login once I figure out how to put it in with the cookies portion.
Application configuration is currently done in a python syntax file PyFileServer.conf - similar to server.conf and I also use paste.pyconfig to read it.
GZip is still unsupport on content-encoding level.
There were some changes in case naming conventions to match PEP-8. Indentation has to be changed but I will write a script to do that later.
Starting next week I will look at some sort of server session storage, for both locking support and dead properties.
Code repositories
There were some problems with the code repositories, after I tried to make some changes in case to the files. CVS doesnt do it very well, and still does not accept the fact that I've renamed RequestServer.py to requestserver.py (even after delete-commit-update-add-commit-update). I've requested for a complete wipe of CVS so that I can check-in everything again from scratch.
Update: I just got this idea. If the CVS problem doesn't get dealt with by BerliOS soon I'll just rename one of the top level directories to something else, that should constitute as a total re-add of my code files. Either way, I lose all that versioning information.
SVN, well anonymous checkout isn't working for some reason:
$ svn checkout svn://svn.berlios.de/pyfilesync
svn: Can't open file '/svnroot/repos/pyfilesync/format': Permission denied
Thanks to my mentor who pointed out that webDAV servers do support Basic. The spec mentions that webDAV servers should support Digest but I missed the fact that they can also support Basic (especially over SSL). I have done both basic and digest, right now it is standalone module (in httpauthentication.py) but digest would be a great addition to paste.login once I figure out how to put it in with the cookies portion.
Application configuration is currently done in a python syntax file PyFileServer.conf - similar to server.conf and I also use paste.pyconfig to read it.
GZip is still unsupport on content-encoding level.
There were some changes in case naming conventions to match PEP-8. Indentation has to be changed but I will write a script to do that later.
Starting next week I will look at some sort of server session storage, for both locking support and dead properties.
Code repositories
There were some problems with the code repositories, after I tried to make some changes in case to the files. CVS doesnt do it very well, and still does not accept the fact that I've renamed RequestServer.py to requestserver.py (even after delete-commit-update-add-commit-update). I've requested for a complete wipe of CVS so that I can check-in everything again from scratch.
Update: I just got this idea. If the CVS problem doesn't get dealt with by BerliOS soon I'll just rename one of the top level directories to something else, that should constitute as a total re-add of my code files. Either way, I lose all that versioning information.
SVN, well anonymous checkout isn't working for some reason:
$ svn checkout svn://svn.berlios.de/pyfilesync
svn: Can't open file '/svnroot/repos/pyfilesync/format': Permission denied
Thursday, July 14, 2005
Digest Authentication
Progress
Worked on digest authentication, and now have it working with both firefox and IE (which never returns the opaque). I wanted to use Paste.login, but webDAV specifically indicated that digest and not basic authentication was to be used.
It was only belatedly that I saw the digest authentication implementation on Python Cookbook. Well I guess it helps to have my code tested alongside a known working copy. :|
Musings
If I separated my application into several layers of middleware, can I use the environ dictionary to pass variables or information between them? like adding a dictionary to value "pyfileserver.config" and putting custom configuration information in there. Apparently I can, but is it a good practice/the-way-to-do-it?
Worked on digest authentication, and now have it working with both firefox and IE (which never returns the opaque). I wanted to use Paste.login, but webDAV specifically indicated that digest and not basic authentication was to be used.
It was only belatedly that I saw the digest authentication implementation on Python Cookbook. Well I guess it helps to have my code tested alongside a known working copy. :|
Musings
If I separated my application into several layers of middleware, can I use the environ dictionary to pass variables or information between them? like adding a dictionary to value "pyfileserver.config" and putting custom configuration information in there. Apparently I can, but is it a good practice/the-way-to-do-it?
Wednesday, July 13, 2005
Almost done with HTTP
PyFileServer
Completed:
+ HTTP functions: OPTIONS, HEAD, GET, POST(modded GET), PUT, DELETE, TRACE (not supported)
+ Partial Ranges for GET (single range only - which is most servers and browsers for download resume)
+ Conditional GETs, PUTs and DELETEs
Working on:
+ GZip support: I realize that the GzipMiddleware did not work well with partial ranges since Content-Range comes on the compressed portion. Back-to-the-drawing-board with regard to GZip support. Also need to know the compressed file size in advance for Range headers, while trying to avoid any sort of buffering of the whole file (compressed or not).
+ Authentication - this is starting on WebDAV, since it requires compulsory authentication - looking it up.
On the shelf:
+ MD5, encryption. Partial and Conditional support for PUT. Content-Encodings for PUT
CVS and SVN repositories updated
Completed:
+ HTTP functions: OPTIONS, HEAD, GET, POST(modded GET), PUT, DELETE, TRACE (not supported)
+ Partial Ranges for GET (single range only - which is most servers and browsers for download resume)
+ Conditional GETs, PUTs and DELETEs
Working on:
+ GZip support: I realize that the GzipMiddleware did not work well with partial ranges since Content-Range comes on the compressed portion. Back-to-the-drawing-board with regard to GZip support. Also need to know the compressed file size in advance for Range headers, while trying to avoid any sort of buffering of the whole file (compressed or not).
+ Authentication - this is starting on WebDAV, since it requires compulsory authentication - looking it up.
On the shelf:
+ MD5, encryption. Partial and Conditional support for PUT. Content-Encodings for PUT
CVS and SVN repositories updated
Tuesday, July 12, 2005
Project: HTTP Status
PyFileServer
Completed:
+ HTTP functions: OPTIONS,HEAD,GET,POST(modified GET),PUT
Working On:
+ DELETE, TRACE
+ Partial Ranges for GET
+ Conditionals: If-Modified-Since, If-Unmodified-Since, If-Range, If-Matched, etc
On the shelf:
+ MD5, encryption
+ Partial Ranges for PUT (currently returns 501 Not Implemented)
+ Conditionals for PUT
To Clarify:
+ if TRACE is implemented by the web server, rather than the application
+ if Content-* headers are applicable to the entity UPLOADED by PUT, that is, if a PUT entity could be under Content-Encoding: gzip and how the application should react.
Completed:
+ HTTP functions: OPTIONS,HEAD,GET,POST(modified GET),PUT
Working On:
+ DELETE, TRACE
+ Partial Ranges for GET
+ Conditionals: If-Modified-Since, If-Unmodified-Since, If-Range, If-Matched, etc
On the shelf:
+ MD5, encryption
+ Partial Ranges for PUT (currently returns 501 Not Implemented)
+ Conditionals for PUT
To Clarify:
+ if TRACE is implemented by the web server, rather than the application
+ if Content-* headers are applicable to the entity UPLOADED by PUT, that is, if a PUT entity could be under Content-Encoding: gzip and how the application should react.
Project: Week 2 Commences
Project Organization
The BerliOS account finally got through! I tried to set up my account all Monday, but apparently their server went down. They just set up an emergency one and its running fine.
CVS was a piece of cake. Install TortoiseCVS, put in the SSH magic bits, and code was up in a few seconds: http://sourceforge.net/docman/display_doc.php?group_id=1&docid=25888#top
SVN took more trouble. http://tortoisesvn.sourceforge.net/?q=node/5 is a guide, but I had to play around with bits and pieces before everything fell into place.
I will probably stick with SVN and delete the CVS repository (when I get around to it) or update both. I work off a development local copy anyway.
For anonymous access to the project: svn checkout svn://svn.berlios.de/pyfilesync
Web page for the project hasn't started. It would just be a description and a link to this site.
Code
A bit slow. There were a couple of false starts, like time wasted on figuring out the mechanics of Python (returning a function callable vs the result of the call, defining application as a function vs as an object), but its all sorted out now. Finishing off the HTTP spec and starting on the WebDAV spec this week.
Some of the things, like MD5 digest and encryption, has been postponed in favor of the WebDAV implementation. MD5 is a dilemma. Because the header goes before the content, calculating and sending the md5 means either compressing and reading the file twice (once just to get the MD5, once to send it), caching/buffering (in memory the entire contents to be sent) or some sort of temporary file buffering.
The BerliOS account finally got through! I tried to set up my account all Monday, but apparently their server went down. They just set up an emergency one and its running fine.
CVS was a piece of cake. Install TortoiseCVS, put in the SSH magic bits, and code was up in a few seconds: http://sourceforge.net/docman/display_doc.php?group_id=1&docid=25888#top
SVN took more trouble. http://tortoisesvn.sourceforge.net/?q=node/5 is a guide, but I had to play around with bits and pieces before everything fell into place.
I will probably stick with SVN and delete the CVS repository (when I get around to it) or update both. I work off a development local copy anyway.
For anonymous access to the project: svn checkout svn://svn.berlios.de/pyfilesync
Web page for the project hasn't started. It would just be a description and a link to this site.
Code
A bit slow. There were a couple of false starts, like time wasted on figuring out the mechanics of Python (returning a function callable vs the result of the call, defining application as a function vs as an object), but its all sorted out now. Finishing off the HTTP spec and starting on the WebDAV spec this week.
Some of the things, like MD5 digest and encryption, has been postponed in favor of the WebDAV implementation. MD5 is a dilemma. Because the header goes before the content, calculating and sending the md5 means either compressing and reading the file twice (once just to get the MD5, once to send it), caching/buffering (in memory the entire contents to be sent) or some sort of temporary file buffering.
Friday, July 08, 2005
Project: WebDAV more
I was looking for an example on gzip support for web applications, and came across this page:
http://www.saddi.com/software/py-lib/
Middleware
Maybe I should have browsed through wsgi sample code right at the start, but reading gzipMiddleWare made something clicked in order to understand how WSGI and middleware actually worked. I guess in Java I had been dealing with pre-filters and post-processors to HTTP requests as separate entities, it did not occur to me that middleware really did both.
It also made me take another look at the Py Tut on generators and iterators as they are used (new to them). The WSGI application either returns a generator (yields) or a iterable as a object or a sequence of strings. If the application returned a single string (like what I did initially), it gets treated inefficiently as a iterable (sequence) of characters.
GZipping: Transfer or Content Encoding
The middleware for gzipping got me confused slightly, since the PEP333 gives:
"(Note: applications and middleware must not apply any kind of Transfer-Encoding to their output, such as chunking or gzipping; as "hop-by-hop" operations, these encodings are the province of the actual web server/gateway. See Other HTTP Features below, for more details.)".
Transfer-Encoding alludes only to "chunking". "Gzipping" is under Content-Encoding and could be supported by the application? Also, the Content-MD5 digest is produced from the gzipped content rather than the original content, if gzip content-encoding is in effect, and ignores Transfer-Encoding. Hope I got it right.
In which case, if gzip is present -> buffering of the sent content may be required to compute the MD5 and Content Length of the compressed data before sending. This may adversely affect performance given the size of the files that might be sent?
Project
On the project, I read more of the WebDAV specification, and it builds on nicely on the existing PyFileServer implementation planned. Locking and supporting arbitary dead properties may require a database to support.
There are a few other python DAV servers mentioned on http://www.webdav.org/projects/, but they are older (since 2000). In any case a WSGI WebDAV server would be great :)
http://www.saddi.com/software/py-lib/
Middleware
Maybe I should have browsed through wsgi sample code right at the start, but reading gzipMiddleWare made something clicked in order to understand how WSGI and middleware actually worked. I guess in Java I had been dealing with pre-filters and post-processors to HTTP requests as separate entities, it did not occur to me that middleware really did both.
It also made me take another look at the Py Tut on generators and iterators as they are used (new to them). The WSGI application either returns a generator (yields) or a iterable as a object or a sequence of strings. If the application returned a single string (like what I did initially), it gets treated inefficiently as a iterable (sequence) of characters.
GZipping: Transfer or Content Encoding
The middleware for gzipping got me confused slightly, since the PEP333 gives:
"(Note: applications and middleware must not apply any kind of Transfer-Encoding to their output, such as chunking or gzipping; as "hop-by-hop" operations, these encodings are the province of the actual web server/gateway. See Other HTTP Features below, for more details.)".
Transfer-Encoding alludes only to "chunking". "Gzipping" is under Content-Encoding and could be supported by the application? Also, the Content-MD5 digest is produced from the gzipped content rather than the original content, if gzip content-encoding is in effect, and ignores Transfer-Encoding. Hope I got it right.
In which case, if gzip is present -> buffering of the sent content may be required to compute the MD5 and Content Length of the compressed data before sending. This may adversely affect performance given the size of the files that might be sent?
Project
On the project, I read more of the WebDAV specification, and it builds on nicely on the existing PyFileServer implementation planned. Locking and supporting arbitary dead properties may require a database to support.
There are a few other python DAV servers mentioned on http://www.webdav.org/projects/, but they are older (since 2000). In any case a WSGI WebDAV server would be great :)
Thursday, July 07, 2005
Project: WebDAV
After initial discussion with my mentor:
* While so far I have been working on the HTTP protocol, perhaps WebDAV is a better system to based off. Its a superset of HTTP but contains more extensions specific to management of files on web servers. Taking some time to read the WebDAV specification.
* Looking at the scope introduced, concentration on the server component is probably best. There would be a skeletal client for testing, in conjunction with any WebDAV test suite used.
* Full time effort is definitely demanded. I tend to work in burst mode myself - getting a lot of production code done (in my perspective) in a few days and falling back to code experimentations for a few days later, but hopefully that gets averaged out. Starting might be slow since it runs with a concurrent summer course till end July
* Writing tests even while coding.
WebDAV test suite:
* litmus: http://www.webdav.org/neon/litmus
Other WebDAV resources:
* akaDAV (in development) : http://akadav.sourceforge.net/
* http://cvs.sourceforge.net/viewcvs.py/webware-sandbox/Sandbox/ianbicking/DAVKit
* While so far I have been working on the HTTP protocol, perhaps WebDAV is a better system to based off. Its a superset of HTTP but contains more extensions specific to management of files on web servers. Taking some time to read the WebDAV specification.
* Looking at the scope introduced, concentration on the server component is probably best. There would be a skeletal client for testing, in conjunction with any WebDAV test suite used.
* Full time effort is definitely demanded. I tend to work in burst mode myself - getting a lot of production code done (in my perspective) in a few days and falling back to code experimentations for a few days later, but hopefully that gets averaged out. Starting might be slow since it runs with a concurrent summer course till end July
* Writing tests even while coding.
WebDAV test suite:
* litmus: http://www.webdav.org/neon/litmus
Other WebDAV resources:
* akaDAV (in development) : http://akadav.sourceforge.net/
* http://cvs.sourceforge.net/viewcvs.py/webware-sandbox/Sandbox/ianbicking/DAVKit
Project: PyFileServer
More definition on the PyFileServer, as it gets developed.
The PyFileServer application maintains a number of mappings between local file directories and "virtual" roots. For example, if there was such a mapping:
C:\SoC\Dev\WSGI -> /wsgi
and the server application is at http://localhost:8080/pyfileserver
=> a request to GET http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/License/LICENSE.txt would return the file C:\SoC\Dev\WSGI\WSGIUtils-0.5\License\LICENSE.txt
This means the file repository shared does not interface directly with the web server but through the application, which is what we want.
* Relative paths are supported and resolved to a normal canonical path, but you cannot relative out of the base path C:\DoC\Dev\WSGI
* Case sensitivity depends on the server OS.
Browsing Directories
When the request GETs and POSTs to a directory url, like http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/ , the response pretty-prints a index of the items in the directory (name, type, size, date last modified).
If POST is used and querystring contains "listitems", the information is returned in a tab-delimited format instead. If querystring contains "listtree", all items in that directory tree structure (not just the directory) listed in a tab-delimited format. This is to support the PyFileSyncClient - normal web-browser usage will GET the html prettyprint.
Downloading Files
When the request GETS and POSTs to a file url, like http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/License/LICENSE.txt, the response returns the file. The following features are planned and mostly come from the HTTP 1.1 specification
FILE REQUEST --> [Conditional Processing] --> [Multipart] --> [Compression] --> [Encryption] --> [MD5] --> Channel Transfer
Conditional Processing
Here it refers to the conditional headers If-Modified-Since, If-Unmodified-Since, etc. They will be supported eventually.
Multiple Partial Content
This is to support multiple partial download - the client would request for different partial content ranges multiple times. Feature is activated by prescence of the Range request header, or by a yet-to-be-defined equivalent in the POST querystring. The server accepts only one Range (may change if I figure out that multipart thingy), multiple or invalid ranges will yield a response of 416 Range not Satisfiable and Content-Range header of '*'. Otherwise the data is returned as 206 Partial Content and Content-Range set accordingly.
Sending partial content always forces the Content-Type to application/octet-stream. Assembly of the file is up to the client. Note that the byte range specified may not compute to Content-Length, since it is the byterange requested BEFORE encryption, compression and other messy stream modifiers.
*Design Note* It might be better to do partial content after compression and encryption, but it means I would have to compress and encrypt the whole file to potentially just send one partial piece of it, and that the client would need to receive all pieces to successfully uncompress and decrypt -> not desirable.
Compression
HTTP protocol specifies identity (none), gzip, zlib or compress. I plan to implement only "gzip" for the initial version, but will make it pluggable so that someone can easily implement some other compression (lossy at your own risk). Feature is activated by corresponding compression identifier in "Accept-Encoding" or equivalent activator in POST querystring.
Encryption (File encryption, not channel encryption like SSL)
Looking at a couple of schemes, but for proof of concept most likely a simple shared key will be implemented. I am unsure as to add it to part of Accept-Encoding and Content-Encoding, or have it separate as an entity header. Accept-Encoding and Content-Encoding seems plausible, etc "gzip/sharedkey". And knowing how to compress it is no help if its encrypted and you don't know how to decrypt it. This will allow clients that support only "gzip" to throw the appropriate errors.
Since it is not part of the HTTP spec, obviously only the PyFileSyncClient will use this functionality.
415 Unsupported Media Type is returned if the server does not understand Compression or Encryption requested. We do this rather than send the file unencrypted.
To support Compression and Encryption, the no-transform cache control directive would be included in the response.
MD5
Server includes it by default. Computes a 16 byte MD5 digest of the body sent and puts it in header Content-MD5. It is up to the client to check it.
Pending Definition
File upload via PUT
Authentication (maintaining session)
The PyFileServer application maintains a number of mappings between local file directories and "virtual" roots. For example, if there was such a mapping:
C:\SoC\Dev\WSGI -> /wsgi
and the server application is at http://localhost:8080/pyfileserver
=> a request to GET http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/License/LICENSE.txt would return the file C:\SoC\Dev\WSGI\WSGIUtils-0.5\License\LICENSE.txt
This means the file repository shared does not interface directly with the web server but through the application, which is what we want.
* Relative paths are supported and resolved to a normal canonical path, but you cannot relative out of the base path C:\DoC\Dev\WSGI
* Case sensitivity depends on the server OS.
Browsing Directories
When the request GETs and POSTs to a directory url, like http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/ , the response pretty-prints a index of the items in the directory (name, type, size, date last modified).
If POST is used and querystring contains "listitems", the information is returned in a tab-delimited format instead. If querystring contains "listtree", all items in that directory tree structure (not just the directory) listed in a tab-delimited format. This is to support the PyFileSyncClient - normal web-browser usage will GET the html prettyprint.
Downloading Files
When the request GETS and POSTs to a file url, like http://localhost:8080/pyfileserver/wsgi/WSGIUtils-0.5/License/LICENSE.txt, the response returns the file. The following features are planned and mostly come from the HTTP 1.1 specification
FILE REQUEST --> [Conditional Processing] --> [Multipart] --> [Compression] --> [Encryption] --> [MD5] --> Channel Transfer
Conditional Processing
Here it refers to the conditional headers If-Modified-Since, If-Unmodified-Since, etc. They will be supported eventually.
Multiple Partial Content
This is to support multiple partial download - the client would request for different partial content ranges multiple times. Feature is activated by prescence of the Range request header, or by a yet-to-be-defined equivalent in the POST querystring. The server accepts only one Range (may change if I figure out that multipart thingy), multiple or invalid ranges will yield a response of 416 Range not Satisfiable and Content-Range header of '*'. Otherwise the data is returned as 206 Partial Content and Content-Range set accordingly.
Sending partial content always forces the Content-Type to application/octet-stream. Assembly of the file is up to the client. Note that the byte range specified may not compute to Content-Length, since it is the byterange requested BEFORE encryption, compression and other messy stream modifiers.
*Design Note* It might be better to do partial content after compression and encryption, but it means I would have to compress and encrypt the whole file to potentially just send one partial piece of it, and that the client would need to receive all pieces to successfully uncompress and decrypt -> not desirable.
Compression
HTTP protocol specifies identity (none), gzip, zlib or compress. I plan to implement only "gzip" for the initial version, but will make it pluggable so that someone can easily implement some other compression (lossy at your own risk). Feature is activated by corresponding compression identifier in "Accept-Encoding" or equivalent activator in POST querystring.
Encryption (File encryption, not channel encryption like SSL)
Looking at a couple of schemes, but for proof of concept most likely a simple shared key will be implemented. I am unsure as to add it to part of Accept-Encoding and Content-Encoding, or have it separate as an entity header. Accept-Encoding and Content-Encoding seems plausible, etc "gzip/sharedkey". And knowing how to compress it is no help if its encrypted and you don't know how to decrypt it. This will allow clients that support only "gzip" to throw the appropriate errors.
Since it is not part of the HTTP spec, obviously only the PyFileSyncClient will use this functionality.
415 Unsupported Media Type is returned if the server does not understand Compression or Encryption requested. We do this rather than send the file unencrypted.
To support Compression and Encryption, the no-transform cache control directive would be included in the response.
MD5
Server includes it by default. Computes a 16 byte MD5 digest of the body sent and puts it in header Content-MD5. It is up to the client to check it.
Pending Definition
File upload via PUT
Authentication (maintaining session)
Project: Architecture
Been thinking for some time to lay out the architecture of the project.
I have taken to calling the project "PyFileSync" unless a better name comes along or my mentor disapproves of this name. It would consist of two components (for the moment):
PyFileServer:
This is the server component that would perform the file-serving/uploading operations
The server acts as a generic file server with the additional features of authentication, transfer verification, compression, file encryption, multipart sending.
PyFileServer is being developed as a WSGI application running over "paster", the default development webserver that comes with Paste.
PyFileSyncClient:
This is the client component that will communicate with the server to perform file-uploading/downloading operations.
The client is responsible for the higher level management that results in the sync'ing of a file repository between the server and the client.
I have taken to calling the project "PyFileSync" unless a better name comes along or my mentor disapproves of this name. It would consist of two components (for the moment):
PyFileServer:
This is the server component that would perform the file-serving/uploading operations
The server acts as a generic file server with the additional features of authentication, transfer verification, compression, file encryption, multipart sending.
PyFileServer is being developed as a WSGI application running over "paster", the default development webserver that comes with Paste.
PyFileSyncClient:
This is the client component that will communicate with the server to perform file-uploading/downloading operations.
The client is responsible for the higher level management that results in the sync'ing of a file repository between the server and the client.
Technical: Initial Contact with WSGI and Paste
Checked out Paste and downloaded WSGIUtils today. Installed svn to check out 3rd party packages. Ran through some of the articles on http://pythonpaste.org.
There was quite a bit of confusion as to what was going on, and the TODO tutorial did not help much. Admittedly after my experience in Java web frameworks I hoped to breeze through this initial learning curve. Getting the tutorial (WebKit and ZPT) running was quick and easy, but there was no clear flow of control to work from.
Still, I would need to learn that flow of control for future purposes. Any recommendations?
There was quite a bit of confusion as to what was going on, and the TODO tutorial did not help much. Admittedly after my experience in Java web frameworks I hoped to breeze through this initial learning curve. Getting the tutorial (WebKit and ZPT) running was quick and easy, but there was no clear flow of control to work from.
With Struts, you knew how things tied together -> how different components of the server were called to process an incoming request, where you redirect control to Actions/Servlets, the order in which stuff was done. I think a large part of this plumbing was hidden in __init__.py and SitePage.py and paster, and the user does not see the connections to index.py/templates.
What I did figure out was to use the ""application(environ, start_response)"" overwrite for the URLparser to hijack control of the request and process it. This ties in neatly with PyFileServer's need to bypass urlparser, since the URL path requested does not go directly to a webserver-shared script or resource but is translated to a directory file path in the file repository outside of the web application.Still, I would need to learn that flow of control for future purposes. Any recommendations?
First Post
This is my first post for this blog, which is set up currently for my Google's Summer of Code 2005 project.
The project is mentored by Ian Bicking and is under the Python Software Foundation. It aims to set up a Python-based Data Serving/Collection Framework.
More information on the project will appear first on this blog as I go along. It would be consolidated at http://cwho.pbwiki.com/ -> once in a while *grinz*
A project website and repository is being set up on BerliOS: http://developer.berlios.de/
I struggled with Blogger's fixed width templates for a while and settled for a standard 1024px width. Apologies in advance to folks with non-standard screen sizes, like my widescreen laptop.
The project is mentored by Ian Bicking and is under the Python Software Foundation. It aims to set up a Python-based Data Serving/Collection Framework.
More information on the project will appear first on this blog as I go along. It would be consolidated at http://cwho.pbwiki.com/ -> once in a while *grinz*
A project website and repository is being set up on BerliOS: http://developer.berlios.de/
I struggled with Blogger's fixed width templates for a while and settled for a standard 1024px width. Apologies in advance to folks with non-standard screen sizes, like my widescreen laptop.
Subscribe to:
Posts (Atom)